Předtím jsem zkontroloval dva různé nástrojeextrahovat text z různých populárních formátů - Text Mining Tool a OCR Terminal. Tyto nástroje umožňují extrahovat text z různých obrazových formátů, formátu PDF a HTML atd. Pokud hledáte mnohem širší nástroj, nástroj, který dokáže extrahovat text z více formátů, teXtracta se vám hodí.
Je to nástroj, který pracuje na principuIFilter. Rozhraní COM vyvinuté společností Microsoft pro službu indexování tak, aby mohla indexovat soubory různých formátů. Tyto indexované soubory jsou poté použity ve Windows 7 / Vista Search, Windows Desktop Search atd. Předtím, než budete moci extrahovat text z různých formátů pomocí teXtracta, musíte mít v počítači nainstalován příslušný IFilters. Chcete-li nainstalovat příslušné IFilters, přejděte sem.
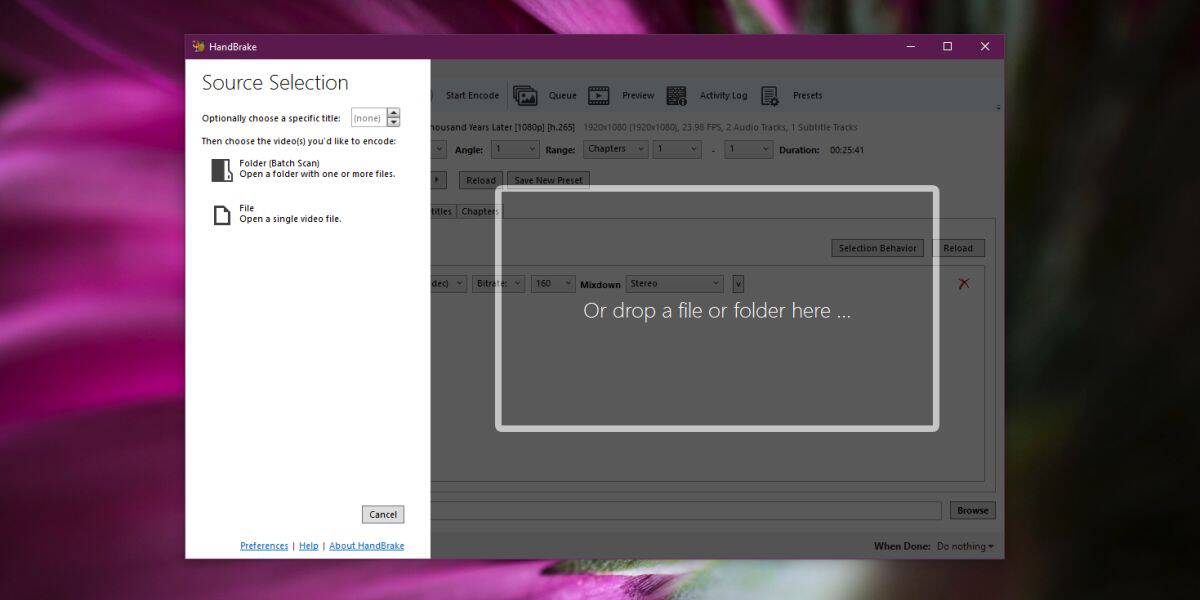
V tomto článku vysvětlím, jak extrahovatJako příklad lze uvést text z dokumentu PDF. Nejprve si stáhněte příslušný IFilter z výše uvedeného odkazu, uchopte teXtracta z odkazu na konci tohoto článku. Nyní načtěte nástroj a vyberte jeden soubor, který chcete zpracovat. Můžete také vybrat složku, tímto způsobem budou zpracovány všechny soubory v této složce. Dále zkontrolujte požadované možnosti, například Zobrazit text, Uložit text a Zahrnout podadresáře.

Až budete hotovi, konečně vyberte filtry, jako jsem si vybral PDF IFilter, jak je znázorněno na obrázku níže.

Když vyberete soubor nebo složku, automaticky se povolí možnosti jako Zahájit zpracování, Pozastavit zpracování a Zastavit zpracování.

Nyní klepnutím na tlačítko Spustit zpracování zahájíte textextrakční proces. Pokud nemáte nainstalovaný správný IFilter, bude vás to okamžitě informovat, jinak proces proběhne hladce. Uvědomte si, že čas, který proces zabere, bude do značné míry záviset na souboru, který lze převést.

Pokud je povolena možnost Uložit text, výstup bude uložen ve formátu txt ve stejném adresáři, kde je soubor nebo složka přítomna.
Stáhněte si teXtracta
Funguje na Windows 2000, Windows XP, Windows Vista a Windows 7. Užijte si to!






Komentáře