Network Latency er ofte den største fjendenetværksadministratorer. Det ser ud til at krybe op overalt og altid ramme dig, når du mindst har brug for det. Derefter har du sandsynligvis aldrig brug for det. Latency kan være sådan, at dit netværk knap bruges. Så hvad kan der gøres ved det? Trin et er at opdage forsinkelser. Derefter skal du måle det og finde det. Først da kan du gøre noget ved at løse det. For at hjælpe dig har vi udarbejdet en liste over netværks latency testværktøjer, der kan hjælpe med at finde og måle latensproblemer.

Inden vi begynder, vil vi forsøge at forklare hvadlatenstid er, og hvad der forårsager det. Dette vil hjælpe dig med bedre at forstå, hvordan de forskellige værktøjer kan hjælpe. Vi undersøger også vigtigheden af latenstid, og hvordan det påvirker netværksbrug. Derefter skal vi se på, hvordan vi kan måle netværks latency. Og da det ikke er nyttigt at finde og måle latens, hvis der ikke gøres noget ved det, diskuterer vi også netværkstidsreduktion. Vi er derefter klar til at præsentere vores liste over de bedste værktøjer til test af netværks latency. Men du kan se, at det ikke kun er en liste, vi gennemgår også kort hvert af værktøjerne.
Hvad er netværksforsinkelse?
I en sætning er netværkets latenstid et mål forden tid det tager for en datapakke at komme fra dens kilde til sin destination. I en ideel verden ville der være nul forsinkelse. Men i virkeligheden vil der altid være nogle. Og selvom latens er uundgåelig, skal man altid sikre sig, at det ikke bliver så vigtigt, at det begynder at påvirke et netværks normale drift.
Flere faktorer bidrager til latenstid. For det første er der forplantningstid. Selvom netværk er hurtige, og bits kører med lysets hastighed, tager det stadig nogen tid at nå destinationen. Og jo længere vej, jo mere tid vil det tage. Af den grund vil latensen mellem to computere, der ligger tusinder af miles fra hinanden, normalt være højere end mellem computere i det samme rum.
En anden medvirkende faktor kaldestransmission forsinkelse. Dette er en forsinkelse, der kan indføres af mediet selv. Det stammer også fra størrelsen på datapakkerne. Større pakker har større latens, da de tager mere tid at levere.
Forsinkelser af router og andre behandlinger er også enkilde til netværksforsinkelse. Selv på knap brugt kredsløb, hvor kø ikke er til stede, er hver router nødt til at manipulere data. F.eks. Skal TTL-headerfeltet dekrementeres.
Faktisk kan mange flere forsinkelser påvirke datatransmission. Vi kan tænke på køforsinkelser, der sker, når data ikke kan sendes med det samme eller lagringsforsinkelse, når det skal cacheres til disk eller hukommelse og derefter hentes.
Måling af forsinkelse
Måling af latenstid kan være mere kompliceret end detudseende. Dette gælder især, når man måler latenstid mellem meget fjerne punkter. Der er nogle få grunde til det, men det skyldes hovedsageligt, at selv enorm latens stadig er relativt kort i størrelsesordenen et par tusindedele af et sekund. Du kan ikke ringe til din ven i den anden ende og fortælle ham "OK, jeg sender dig en pakke, fortæl mig når den ankommer" og måle forsinkelsen. Chancerne er, at pakken kommer, inden du endda er færdig med at tale. Glem timing det.
Typisk måles latens ved at sende enpakke, der returneres til afsenderen og måler den tid, det tager for svaret at komme tilbage. Det er denne rundrejsetid betragtes som en forsinkelse. Der er nogle få ulemper ved denne evalueringsmetode. Hvis returvejen for eksempel er anderledes, fortæller latenstallet dig ikke, hvilken af frem- eller returstier der oplever latenstid.
Et andet muligt problem er, at typerne afpakker, der bruges til måling af latenstid - typisk ICMP-anmodninger og svar - behandles ikke altid af netværksenheder med samme prioritet som nogle andre netværkstrafik.
Hvorfor er forsinkelse vigtig?
Det lette svar her er indlysende: fordi når latenstiden bliver for høj, kan det påvirke netværkets anvendelighed. Så det er ikke latenstid i sig selv, der er vigtigt, men at se det er. Usædvanligt høj – eller højere end sædvanlig – latenstid er ofte et tegn på, at der er noget galt med netværket eller på netværket. Det meste af tiden vil det være konsekvensen af overbelastning. Netværk er som motorveje, og når der er for megen trafik, går tingene langsommere, og du får høj latens.
Men målt latens er ikke altid en indikationaf et netværksproblem. Da vi normalt måler latenstid ved at måle tur-retur-tid, kan en anden kilde til latenstid være den fjerne enhed. Hvis enheden er meget travlt med at gøre, hvad det er, den skal gøre, svarer den muligvis ikke med det samme på ICMP-anmodningen, den har modtaget fra testværten. Når det sker, vil det blive opfattet som netværks latency, men det har faktisk intet at gøre med netværket, og din latenstidsmåling giver dig ikke en anelse om dette.
Tilsvarende kunne brugere opleve latenshar intet at gøre med netværket. Applikations latenstid er muligvis lige så almindelig som netværks latency. Når serverne bliver overbelastede, reagerer starten langsomt. Ligesom netværk, når de bliver overbelastede. Men server- og applikations latenstid er bestemt ikke emnet i dag.
Reduktion af netværksforsinkelse
Det er en (irriterende) ting at opleve forsinkelseog det er en anden ting at måle det, men hvad er det godt, medmindre du finder en måde at reducere det på. Der er flere måder, du kan gå på for at gøre dette på. I et nøddeskal afhænger det af, hvad der forårsager det, hvordan man løser høj latenstid. Og da den mest almindelige årsag til latenstid er overudnyttelse af netværket, så lad os se, hvad der kan gøres ved det.
Netværkskredsløb er ikke ubegrænset, og når de erbliver overudnyttet, overbelastning opstår, og brugerne oplever høj latenstid. Det fungerer nøjagtigt som motorvejstrafikken. Dette gælder især for WAN-kredsløb, der ofte har meget begrænset båndbredde.
Så for at reducere latenstid er den bedste måde - det ville duhar gættet det - for at reducere netværksforbruget. Men det er selvfølgelig ikke altid muligt. Det er her netværksoptimering kommer ind. Vi kunne skrive en hel artikel om WAN-optimering. Faktisk gjorde vi for nylig. Og der er mange værktøjer, du kan bruge til at hjælpe med denne opgave.
De bedste værktøjer til måling af forsinkelse
Som vi nu ved, skal du først løse problemet med forsinkelsenødt til at måle det og finde, hvor det kommer fra. Det er her de værktøjer, vi er ved at afsløre, kan hjælpe. Nogle vil blot måle latens, mens andre vil hjælpe dig med at finde det. Andre måler endnu båndbreddeanvendelse, hvilket kan hjælpe, da vi ved, at overforbrug er den vigtigste årsag til høj latenstid. Værktøjerne er grupperet efter type snarere end efter præference.
1 - SolarWinds Network Performance Monitor (Gratis prøveversion)
SolarWinds er en af de mest kendte producenter afnetværksadministrationsværktøjer. Virksomheden har eksisteret i aldre og er også berømt for sine flere gratis værktøjer, der hver især imødekommer et specifikt behov hos netværksadministratorer. Flere af de gratis værktøjer blev gennemgået på disse sider, da vi diskuterede de bedste TFTP-servere på de bedste syslog-servere.
SolarWinds Network Performance Monitor ellerNPM, er SolarWinds flagskibsprodukt. Det er sandsynligvis et af de bedste SNMP-båndbreddeovervågningsværktøjer, det er fyldt med så mange funktioner, at vi kunne tale om det i timevis. Værktøjets bedste fordel er sandsynligvis dets enkelhed. Men denne enkelhed kommer ikke til prisen for fleksibilitet. Dashboards, visninger, diagrammer og rapporter kan tilpasses fuldt ud til dine præferencer eller behov. Værktøjet kan indstilles på få minutter, og det kan skaleres fra det mindste netværk til enorme med tusinder af enheder.
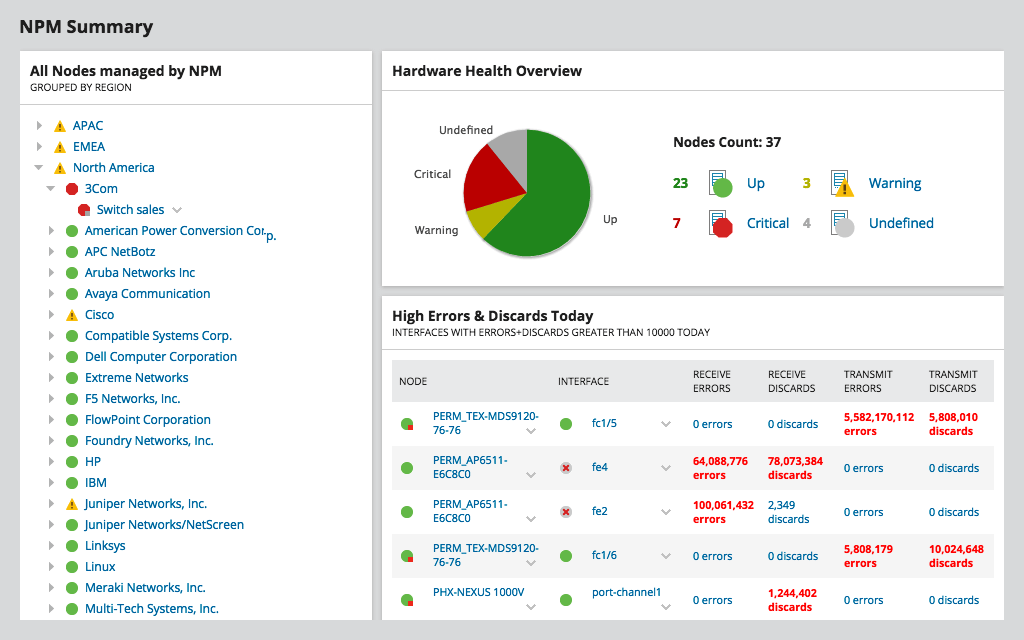
NPM måler ikke netværkets latenstid direkte,selvom. Men ved at give dig detaljerede oplysninger om brugen af båndbredde på alle dele af dit netværk, giver det dig hurtigt mulighed for at identificere problemer, hvor overbelastning kan være årsagen til høj latenstid.
NPM bruger SNMP til periodisk at pollere dine enhederog læse deres grænsefladetællere, beregne brugen af båndbredde og vise det som grafer. Konfiguration af værktøjet kræver kun, at du specificerer en enheds IP-adresse og community-streng. Avancerede funktioner giver dig mulighed for at oprette netværkskort og vise den kritiske sti mellem to enheder, en fantastisk funktion, når du fejlsøger latens.
Prisfastsættelse for Network Performance Monitor starter ved $ 2 955. Hvis du gerne vil prøve værktøjet, før du køber det, er en fuldt udstyret 30-dages prøveversion tilgængelig.
2 - SolarWinds NetFlow Traffic Analyzer (Gratis prøveversion)
Et andet fremragende produkt fra SolarWinds, theNetFlow Traffic Analyzer kan give administratorer en mere detaljeret oversigt over netværkstrafik. Det vil ikke kun vise dig udnyttelse og potentiel forsinkelse, men det vil også vise dig, hvor det finder sted, og ofte hvad der forårsager det. Værktøjet giver detaljerede oplysninger om, hvad den observerede trafik er. For eksempel giver værktøjet dig mulighed for at finde ud af, hvilken type trafik, eller hvilken bruger der bruger den mest båndbredde. NetFlow Traffic Analyzers dashboard har flere tilgængelige nyttige visninger, såsom top-applikationer, topprotokoller eller top talkers.
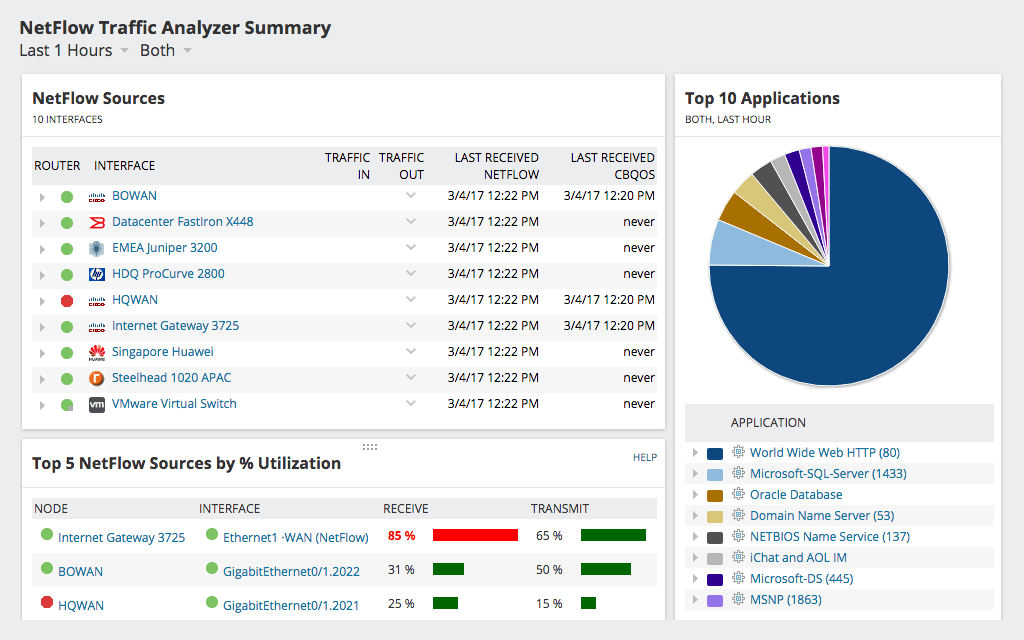
SolarWinds NetFlow Traffic Analyzer brugerNetFlow-protokol til at indsamle detaljerede brugsoplysninger fra netværksenheder. NetFlow-protokollen, der oprindeligt blev oprettet af Cisco, giver enheder mulighed for at sende detaljerede oplysninger om hver netværks “samtale” eller flow til en NetFlow-samler og analysator, såsom NetFlow Traffic Analyzer. Denne information indeholder flere elementer, der kan bruges til at analysere trafikken. Mange andre producenter end Cisco inkluderer også NetFlow-funktionalitet eller en tilsvarende i deres udstyr, nogle gange kalder det et andet navn. For nylig er NetFlow-protokollen blevet standardiseret som IPFIX eller IP Flow Information Exchange af IETF. SolarWinds NetFlow Traffic Analyzer fungerer med alle varianter af protokollen, hvilket gør den til et fremragende valg.
SolarWinds NetFlow Traffic Analyzer er enekstra modul, der installeres oven på Network Performance Monitor. Priser starter ved $ 1 915 og varierer afhængigt af antallet af værter. Og ligesom med de fleste SolarWinds-betalte produkter er en gratis prøveversion tilgængelig.
3 - Paessler PRTG
Paessler Router Traffic Grapher, eller PRTG, eret andet overvågningsværktøj til båndbredde. Og det er en af de nemmeste og hurtigste at installere. Paessler hævder, at du kunne være i gang inden for få minutter og virkelig, det tager ikke meget tid, selvom det kræves, at opsætte produktet. Produktet har en automatisk opdagelsesfunktion, hvilket betyder, at det vil scanne dit netværk og automatisk tilføje de komponenter, det finder.
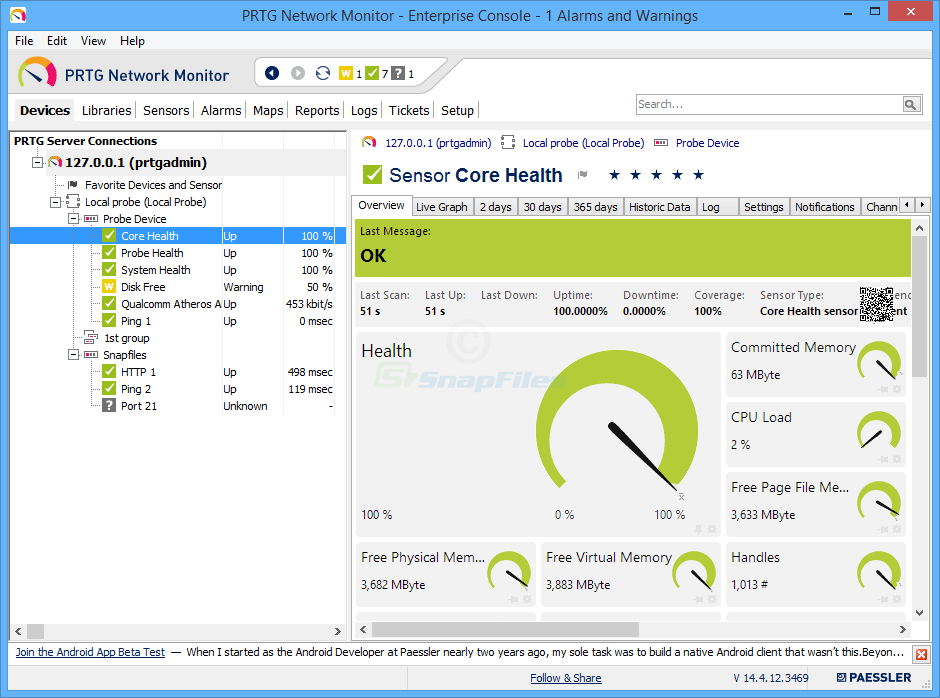
PRTG kommer standard med flere brugergrænseflader,så du kan vælge den der bedst passer til dine behov. Der er en indbygget Windows-konsoleapplikation, der er også en Ajax-baseret webgrænseflade, og der er mobile apps til Android og iOS. Og det gør stor brug af hver platformsfunktioner. F.eks. Giver mobile apps dig adgang til enhver enheds detaljer ved blot at scanne en QR-kodemærkning, der er påført den. Selvfølgelig giver Windows-konsollen dig mulighed for at udskrive disse etiketter.
PRTG bruger en kombination af teknologier til detsovervågning. Det vil bruge SNMP-overvågning, men også WMI til Windows-enheder og NetFlow og Sflow, to lignende, men konkurrerende flowanalyseteknologier. Og værktøjet har flere sensorer, der er specifikt designet til at måle latenstid. Der er en QoS-sensor, der måler returrejse, en Cisco IP SLA-sensor og en Ping-sensor.
4 - ManageEngine NetFlow AnalYzer
ManageEngine NetFlow Analyzer er en andenNetFlow-baseret overvågningsværktøj, der indeholder nogle avancerede latensovervågningsfunktioner. Værktøjet giver en detaljeret oversigt over netværksudnyttelse og trafikmønstre. Dens webbaseret brugergrænseflade giver dig mulighed for at se trafik efter applikation, efter samtale, efter protokol og mere. Værktøjets omfattende dashboard er en af dets bedste funktioner. Det tilbyder nogle af de bedste alsidigheder og giver dig mulighed for at medtage de ønskede data. Og for on-the-go-administratorer er der mobile apps tilgængelige.
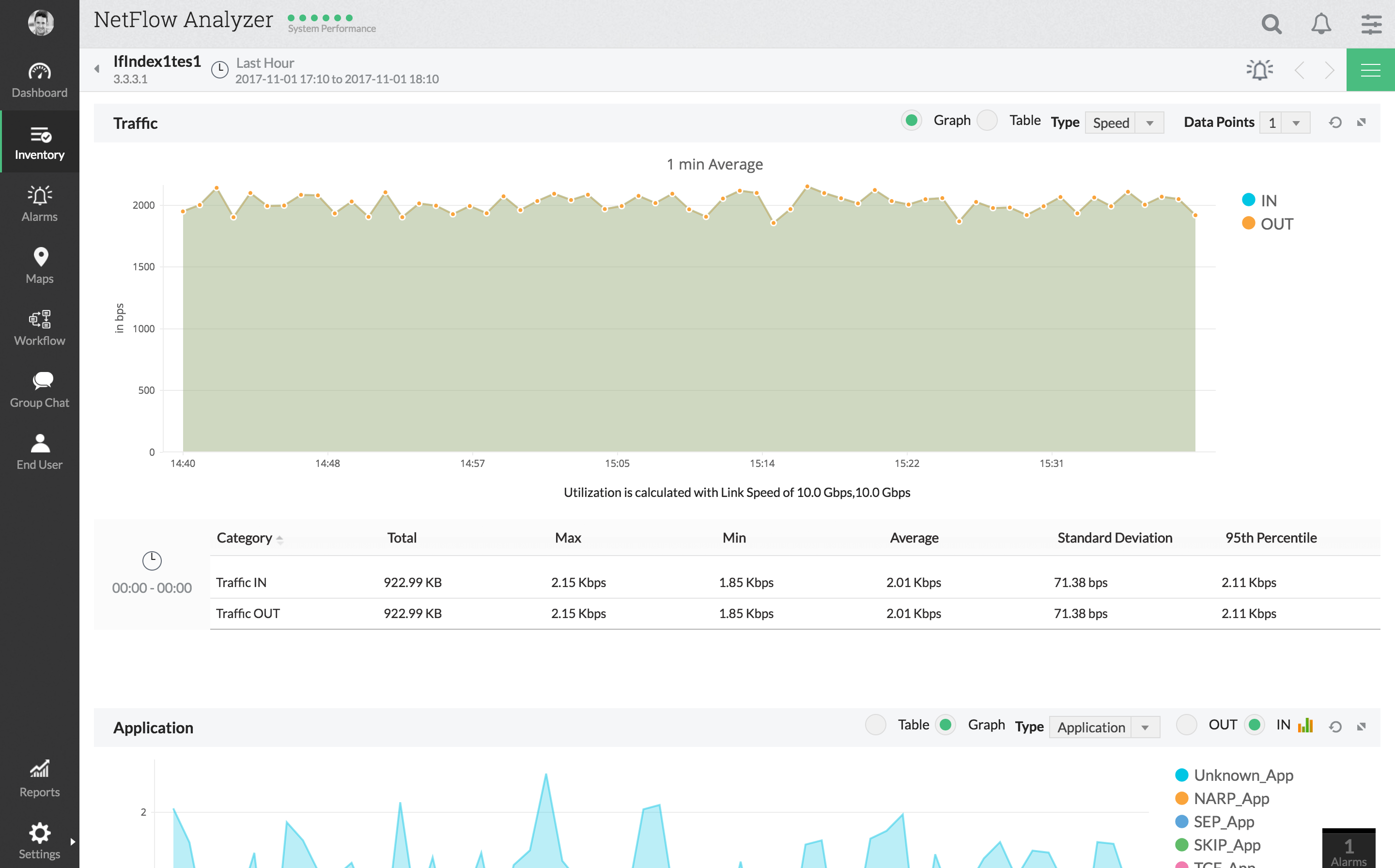
ManageEngine NetFlow Analyzer understøtterflere flowteknologier, herunder NetFlow, IPFIX, J-flow, NetStream og et par andre. Som en bonus har også den fremragende integration med Cisco-enheder med support til justering af trafikformning og / eller QoS-politikker lige fra værktøjet.
Og til latensmåling har dette værktøj en WAN Round Trip Time (RTT) skærm, som giver dig mulighed for at overvåge WAN-tilgængelighed, latenstid og servicekvalitet.
5 - PingPlotter
På trods af sit vildledende navn er PingPlotter detfaktisk en grafisk Traceroute-software, der kan hjælpe med at løse netværksproblemer. Dette diagnostiske værktøj tegner latens og pakketab mellem din computer og et mål. Det giver dig mulighed for at visualisere oplysningerne, fremskynde din fejlfindingsproces og kan hjælpe med at opbygge en sag, hvis du har brug for at overbevise nogen om, at der findes et problem på deres ende.
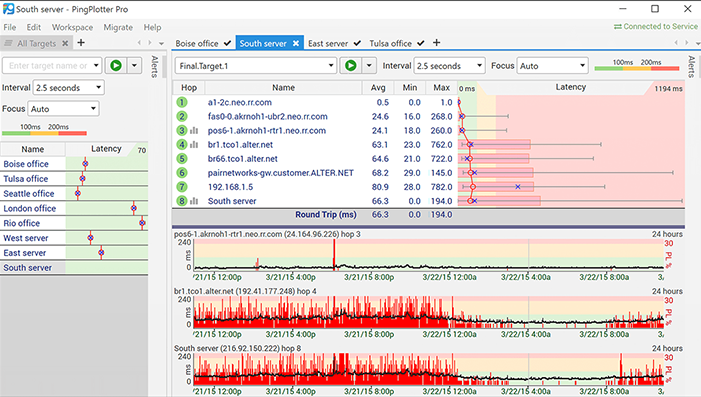
PingPlotter tegner netværkets ydeevne på allehop mellem computeren, hvor du kører den og et målwebsted, server eller enhed. Værktøjet tester stien til enhver enhed, der kan nås på netværket. Det viser, hvor latens sker, hvilket sparer dig for meget diagnosticeringstid.
Selvom det er nyttigt at have præstationsstatistikker,de fortæller dig kun, at netværket mislykkedes - eller ikke mislykkedes - under testen, og hvor fejlen er. PingPlotter har en nyttig tidslinjefunktion, der giver et dybere forståelsesniveau ved at vise nøjagtigt, når problemer opstår. Dette giver dig mulighed for at skelne mellem en konsekvent fiasko gennem hele testen og en kort periode med alvorlig fiasko. Det kan også hjælpe med at korrelere fejlen med andre samtidige begivenheder.
6 - MultiPing
MultiPing er et andet produkt med nogetvildledende navn. Selvom det primært bruger Ping til at opnå sin præstation, er MultiPing virkelig et overvågningssystem, ligesom SolarWinds 'NPM. Selvfølgelig bruger Ping snarere at SNMP betyder, at de oplysninger, du får, er meget forskellige. Forvent ikke at se båndbreddebrug med dette værktøj. En ting, du dog vil se, er forsinkelse. Og ligesom båndbreddemonitorer vil plotte grafer af båndbredde over tid, vil denne en plot kortvarighed over tid.
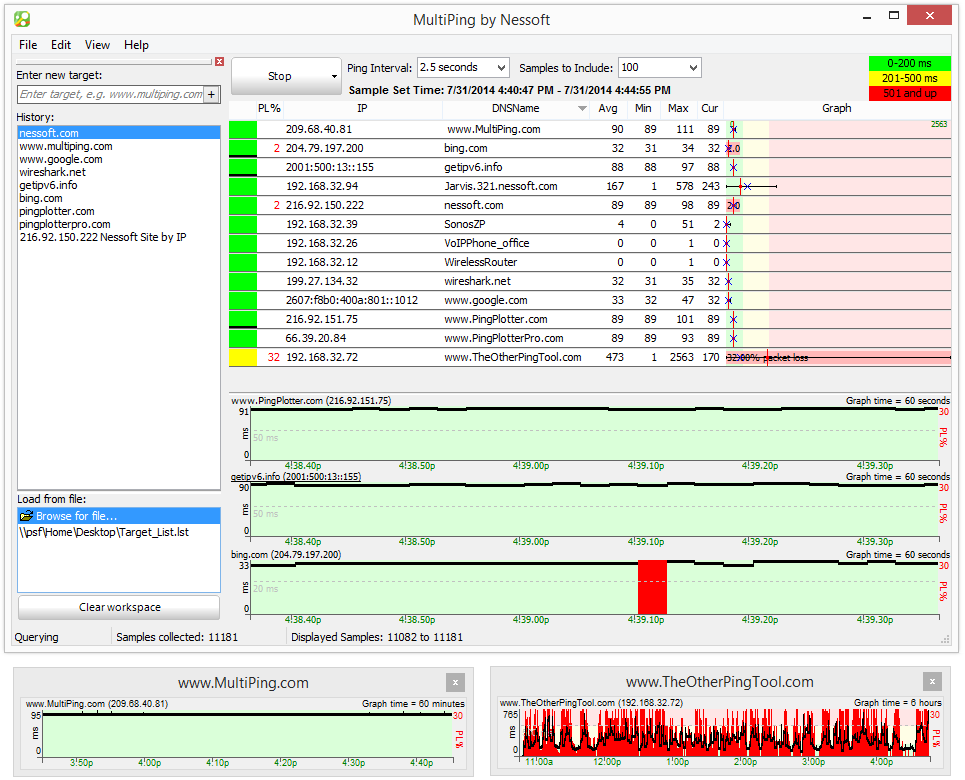
MultiPing viser dig pakketab i procentsamt minimum, gennemsnit og maksimal forsinkelse. Det har auto-discovery, hvilket gør opsætningen til en super nem opgave. Produktets brugergrænseflade kan konfigureres efter din smag ved at placere dets forskellige komponenter, som du finder passende. Systemet har også advarsler, der kan underrette dig, når parametre er uden for rækkevidde. Ud over meddelelser kan programmer startes på alarmer.
7 - Ping
Du behøver ikke at downloade eller installere noget tiltest latency, dog. Ping er en kommando, der er indbygget lige i de fleste moderne operativsystemer. I en nøddeskal sender Ping en række ICMP-ekko-anmodninger til mål-IP-adressen og venter på, at den skal svare med tilsvarende ICMP-ekko-svar. Forsinkelsen mellem anmodningen og svaret kaldes returrejse, der også benævnes latens. Og når det ikke modtager et svar på en af dets anmodninger, antager hjælpeprogrammet, at enten anmodningen eller svaret gik tabt i transit og kompilerer pakketapinformationen, der vises, når kommandoen er færdig med at udføre.
8 - Traceroute (eller Tracert)
Tilsvarende Traceroute – eller Tracert, hvis du kommerfra Windows-verdenen - kan også bruges til forsinkelse-testformål. Dette er en anden kommando, der er indbygget i de fleste operativsystemer. Den bruger den samme type ICMP-anmodninger og svar som Ping, men det gør det på en måde, der giver det mulighed for individuelt at teste responstiden - eller latenstiden - for hvert netværkssegment langs stien. Dette er endnu bedre end Ping, da det kan give dig en ret god idé om, hvor det meste af forsinkelsen sker. Så dette værktøj kan ikke kun måle, men også finde latens.









Kommentarer