Det ser ud til, at netværk aldrig er hurtige nok. Virkelig er netværkets ydeevne langt det mest mest klagede emne, når det kommer til netværkssystemer. Der er dog en grund til det. Netværkets ydeevne - eller mangel på dem - er sandsynligvis det mest synlige problem fra en brugers synspunkt. Så når de har til opgave at fejlfinde netværkspræstationsproblemer, skal netværksadministratorer vide, hvad de skal kigge efter, hvor de skal kigge efter det, og de skal have adgang til de rigtige værktøjer.
I dag ser vi grundigt på fejlfinding af netværkets ydelsesproblemer.

Vi starter, som vi ofte gør, med en kilometerhøjdese, hvad netværkets ydeevne er. Efterhånden som vi kommer nærmere, får vi et mere detaljeret kig på nogle af de faktorer, der typisk påvirker ydelsen af computernetværk. Vi vil først diskutere båndbredde og gennemstrømning, der til en vis grad er to sider af den samme mønt. Dernæst skal vi tale om latenstid og forsinkelse, to målinger, der ofte er forvirrede. Vi gør vores bedste for at kaste lys over emnet.
Vores næste forretningsordre vil være jitter, en afde mest præstationseffektive aspekter af netværk. Og sidst, men ikke mindst, diskuterer vi fejl, som undertiden kan være konsekvensen og undertiden symptomerne på andre problemer. Og da det at have adgang til de rette værktøjer er meget vigtigt, når du fejler problemer med netværkets ydeevne, skal vi se på et par af de bedste netværksovervågningsværktøjer, der kan hjælpe med din fejlfinding.
Om netværkets ydeevne
Wikipedia definerer netværkspræstation på en meget forenklet måde. ”Netværkets ydeevne henviser til målinger af servicekvalitet på et netværk, som kunden ser”. Der er tre vigtige begreber i denne definition. Den første har at gøre med måleydelse. Dette er kritisk. Netværkets ydeevne er noget, der måles. Det andet vigtige koncept er kvalitet. Ydeevne henviser til kvalitet. Og sidst, men bestemt ikke mindst, kunden. Ydeevne er noget, der ses eller opleves af en bruger af netværket, ikke kun ved måleværktøjer. Derfor er det så vigtigt at have netværkspræstationskontrolværktøjer, der er i stand til at foretage målinger fra en brugers perspektiv.
Men er ikke brugerens perspektiv megetsubjektivt koncept, der kan være svært at evaluere? Det er bestemt, men ved hjælp af de rigtige værktøjer og teknologier kan det opnås. Nøglen er at vide, hvordan hver måling påvirker den opfattede præstation, og det er netop vores emne i dag.
Sagt anderledes er et netværks ydelse detsevnen til at imødekomme brugerens forventninger. Dette er vigtigt, da det indebærer, at et netværks ydelse er brugerafhængig. Nogle tilfælde af netværksbrug har meget små ydelseskrav, mens andre har brug for mere. Et godt præstationsnetværk er et, hvor den faktiske ydelse matcher brugen, hvilket giver brugerne en opfattelse af, at alt fungerer godt.
Faktorer, der påvirker netværkets ydelse
Flere ting kan påvirke den opfattede præstation. Nogle faktorer er ikke engang netværksrelaterede. For eksempel kan en server, der reagerer langsomt, fortolkes som et tegn på forringelse af netværkets ydeevne. Dette er endnu en grund til, at vi er nødt til at vide, hvad netværksfaktorer spiller, da det gennem en eliminationsproces tillader at identificere ikke-netværkspræstationsproblemer.
I de følgende afsnit skal vi se påhvilke faktorer og parametre der interagerer for at give brugerne opfattelsen af god - eller ikke så god - præstation. Nogle af disse faktorer er fysiske egenskaber ved netværk, som vi typisk ikke har kontrol over, mens andre er elementer, der ofte kan forbedres, hvilket giver brugerne opfattelsen af bedre ydeevne.
Båndbredde og gennemstrømning
Båndbredde og gennemstrømning er på en måde to sideraf den samme mønt. Der er desuden ikke en klar sondring mellem de to udtryk, og de bruges ofte om hverandre. Vi føler, at dette er en fejl, da de i virkeligheden er noget forskellige koncepter.
Båndbredde henviser typisk til dataforretningenkapacitet i et netværkssegment efter tidsenhed. Det udtrykkes normalt i multipla af bit pr. Sekund, hvor megabits per sekund (Mbps) og gigabits per sekund (Gbps) er det mest almindelige. For eksempel har en ældre hurtig-Ethernet-forbindelse en båndbredde på 10 Mbps. Båndbredde er ikke noget, der måles, og det er heller ikke noget, der varierer over tid og med øget brug. Det er en iboende egenskab ved et netværk. Nogle kredsløb bruger teknologier, hvor båndbredde let kan øges eller reduceres, men i de fleste situationer er det en fast parameter, der ikke kan ændres.
Med hensyn til gennemstrømning henviser det til det faktiske beløbaf data, der med succes transmitteres af tidsenheden. Tshroughput er begrænset af tilgængelig båndbredde såvel som det tilgængelige signal-til-støj-forhold, netværksfejl og hardwarebegrænsninger. De fleste af de samme faktorer påvirker netværkets ydelse påvirker gennemstrømningen. Faktisk er gennemstrømning en tæt fætter til præstation. Alt andet lige, jo højere gennemstrømning, jo højere er den opfattede præstation.
I forbindelse med den opfattede netværksydelse,båndbredde og gennemstrømning er vigtige, fordi når båndbreddebrug nærmer sig den maksimale kapacitet i et netværkssegment, forringes ydelsen normalt markant. Dette er grunden til, at selvom båndbredde er fast, skal båndbreddebrug overvåges.
Forsinkelse og forsinkelse
Meget som båndbredde og gennemstrømning er derofte en masse forvirring mellem forsinkelse og forsinkelse. Dette er en anden situation, hvor to koncepter bruges om hverandre. Begge har at gøre med den tid det tager for data at rejse fra sin kilde til sin destination. Latency beskrives ofte som tiden fra kilden, der sender en pakke til den destination, der modtager den. Det kan også henvise til forsinket tid på rundtur, der omfattede envejs latency fra kilde til destination plus envejs latens fra destinationen tilbage til kilden. Faktisk bruges ofte tur-retur latency, hovedsageligt fordi den kan måles fra et enkelt punkt. Rundrejse-latenstid udelukker normalt den tid, som et destinationssystem bruger til at behandle pakken og udstede svaret.
RETTET LÆSNING: 6 Værktøjer til styring af netværkskonfiguration for alle dine enheder
Latency er en anden fysisk egenskab vednetværk. Det er en faktor for afstanden mellem kilden og destinationen og lysets hastighed, som det i øvrigt også er den hastighed, hvormed data bevæger sig over alle typer medier. Ligesom båndbredde er latens en fast parameter. Den eneste måde at reducere det på er at bevæge kilden tættere på destinationen. Ved at reducere afstanden med ca. 100 km fjernes ca. 1 millisekund forsinkelse.
Der er ganske mange andre faktorer, der tilføjer nogleforsinkelse til netværks transmissionerne. F.eks. Opstår køforsinkelse, når en gateway modtager flere pakker fra forskellige kilder, der kører mod den samme destination. Da kun en pakke typisk kan transmitteres ad gangen, skal nogle af dem stå i kø for transmission, hvilket medfører en yderligere forsinkelse. Der opstår også behandlingsforsinkelser, mens en gateway bestemmer, hvad der skal gøres med en nyligt modtaget pakke. Bufferbloat kan endvidere medføre øgede forsinkelser i en størrelsesorden eller mere. Kombinationen af udbredelses-, kø- og behandlingsforsinkelser resulterer ofte i en kompleks og variabel netværkstidsprofil.
Forsinkelse og forsinkelse er de vigtigste faktorer, der påvirkeropfattet netværksydelse. Heldigvis kan de let måles enten enkelt- eller dobbeltbehandlet. Måling med dobbelt ende, som beskrevet tidligere, hvis det ofte foretrækkes, da det ignorerer destinationens behandlingsforsinkelse og giver en sand måling af netværkets latenstid.
jitter
Jitter er netværkets største fjende kommunikation og selvom det er relativt let at forklare, er det detnoget mere kompliceret at forstå, hvordan og hvorfor det kan have en så negativ indvirkning på datatransmissioner. Lad os prøve at forklare. Kort sagt, jitter er en variation i forsinkelse. Der er flere faktorer, der kan forårsage jitter. Faktisk påvirker mange af de samme faktorer, der påvirker forsinkelsen, også jitter. For eksempel er køforsinkelser direkte relateret til køens længde. Og da en typisk kø konstant varierer i længde, gør det også forsinkelse, derfor jitter.
Ting med jitter er, at det ikke påvirkeral netværkstrafik på samme måde. Når forsinkelser varierer betydeligt mellem de flere pakker, der komponerer en meddelelse (dvs. i situationer med store jitter), kunne pakkerne ankomme til deres destination ude af rækkefølge. Lad os f.eks. Tage en transmission, der består af fire pakker, der transmitteres med 10 ms intervaller. Den første møder 20 ms latens, den anden 60 ms, den tredje 40 ms og den sidste 20 ms. Jeg sparer dig for den kedelige matematik, men i en sådan situation kommer den første pakke først, efterfulgt af den fjerde, derefter den tredje og til sidst den anden. I nogle situationer ville dette ikke være et problem. For eksempel, hvis vi har at gøre med en filoverførsel, er pakkerne nummereret i rækkefølge og kan let samles igen i den rigtige rækkefølge i den modtagende ende. På den anden side, hvis det, vi har, er trafik i realtid, såsom en streaming video eller en VoIP-samtale, er vi i problemer, da pakker ikke kan samles korrekt igen, hvilket resulterer i pixel video eller forvirret lyd. Fra en brugers synspunkt har vi et ydelsesproblem.
fejl
I en vis grad er netværksfejl en andenfaktor, der påvirker netværkets ydelse. Bitfejl refererer til antallet af bit i en datastrøm modtaget via en kommunikationskanal, der er ændret på grund af støj, interferens, forvrængning eller bit synkroniseringsproblemer. Bitfejlhastigheden eller bitfejlforholdet (BER) er antallet af bitfejl divideret med det samlede antal overførte bit i et givet tidsinterval. Det udtrykkes ofte som en procentdel.
Mens netværk er meget robuste og robuste,de vil for det meste gendanne sig fra disse fejl ved hjælp af flere metoder, herunder indbyggede fejlkorrektionsskemaer eller videresendelse af forkerte data. Men selvom disse kan være acceptable, forårsager de ofte unødvendige forsinkelser, øgede jitter og alskens brugeropfattede ydelsesproblemer.
LÆS OGSÅ: Pakketab - Hvordan man måler og hvordan man løser dem
De bedste værktøjer til fejlfinding af netværkets ydeevne
Mens der er mange værktøjer til målingnetværkets ydeevne, ikke alle af dem er lige så funktionelle som de få, vi har valgt til dig. De bedste viser ikke kun båndbredde, men også adskillige båndbreddepåvirkende målinger, som f.eks. Latenstid eller jitter, hvorved du hurtigt hjælper dig med at fejlfinde udstedt netværksydelse.
1. SolarWinds Network Performance Monitor (GRATIS PRØVEVERSION)
SolarWinds er en af de mest kendte leverandører af netværks- og systemadministrationsværktøjer. Det er berømt for sine mange fremragende værktøjer til netværksadministration. Blandt de mest berømte SolarWinds produkter er NetFlow Traffic Analyzer og Server- og applikationsmonitor. Virksomheden er også anerkendt for at lave en håndfuld fremragende gratis værktøjer, der hver især imødekommer et specifikt behov fra netværks- og systemadministrator. Det Avanceret undernetberegner og Kiwi Syslog Server er to fremragende eksempler på disse gratis værktøjer.
SolarWinds'Flagskibsprodukt kaldes Network Performance Monitor, eller NPM. Dette er en komplet netværksovervågningsløsning med stor funktionalitet. Det SolarWinds NPM afstemmer enhver aktiveret enhed ved hjælp af SNMP-protokollenat læse deres operationelle målinger og grænsefladetællere. Det gemmer resultaterne i en SQL-database og bruger de pollede data til at oprette grafer, der viser hvert WAN-kredsløbs brug samt andre vigtige målinger.
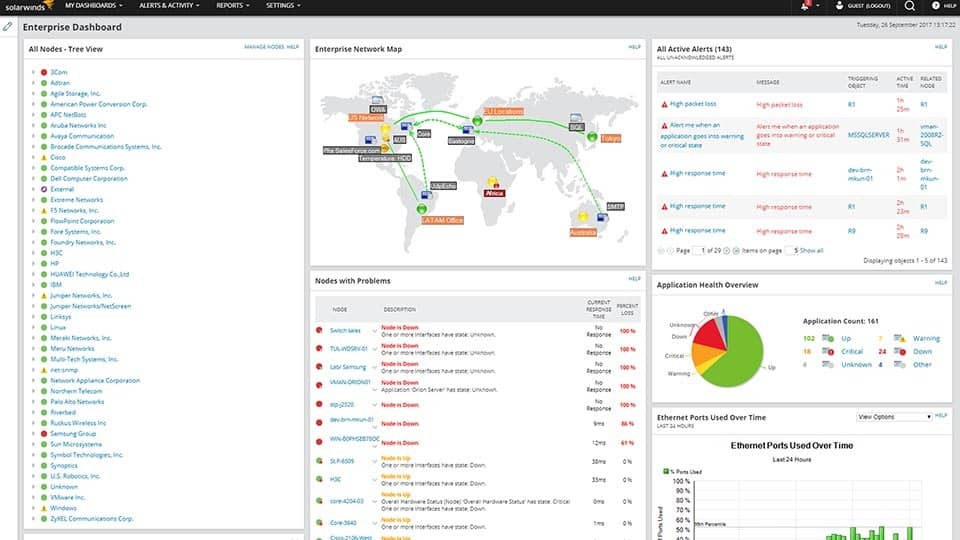
- GRATIS PRØVEVERSION: SolarWinds Network Performance Monitor
- Download link: https://www.solarwinds.com/network-performance-monitor/registration
SolarWinds Network Performance Monitor kan prale afet brugervenligt GUI. Med det er tilføjelse af en enhed så simpelt som at specificere dens IP-adresse eller værtsnavn og SNMP-community-streng. Værktøjet spørger derefter enheden, viser alle de tilgængelige SNMP-parametre og giver dig mulighed for at vælge dem, du vil overvåge og vise på dine grafer.
Priserne for SolarWinds Network Performance Monitor starter ved $ 2 995 og varierer afhængigt af antallet af enheder, der skal overvåges. Et detaljeret tilbud kan fås ved at kontakte SolarWinds salgsteam.
Hvis du ønsker at prøve produktet, før du køber det, er en gratis 30-dages prøveversion tilgængelig, som det er for de fleste SolarWinds-produkter.
2. ManageEngine OpManager
Det ManageEngine OpManager er en komplet styringsløsning, der vilimødekomme de fleste overvågningsbehov. Værktøjet kan køre på enten Windows eller Linux, og det er fyldt med fremragende funktioner. F.eks. Kan dens auto-discovery-funktion grafisk kortlægge dit netværk, hvilket giver dig et unikt tilpasset betjeningspanel.
Værktøjets instrumentbræt er et andet af dets stærkepoint. Det er super nemt at bruge og navigere og har drill-down funktionalitet. Hvis du er i mobilapps, er de tilgængelige til tablets og smartphones og giver dig mulighed for at få adgang til systemet hvor som helst. Alt i alt er dette et meget poleret og professionelt produkt.
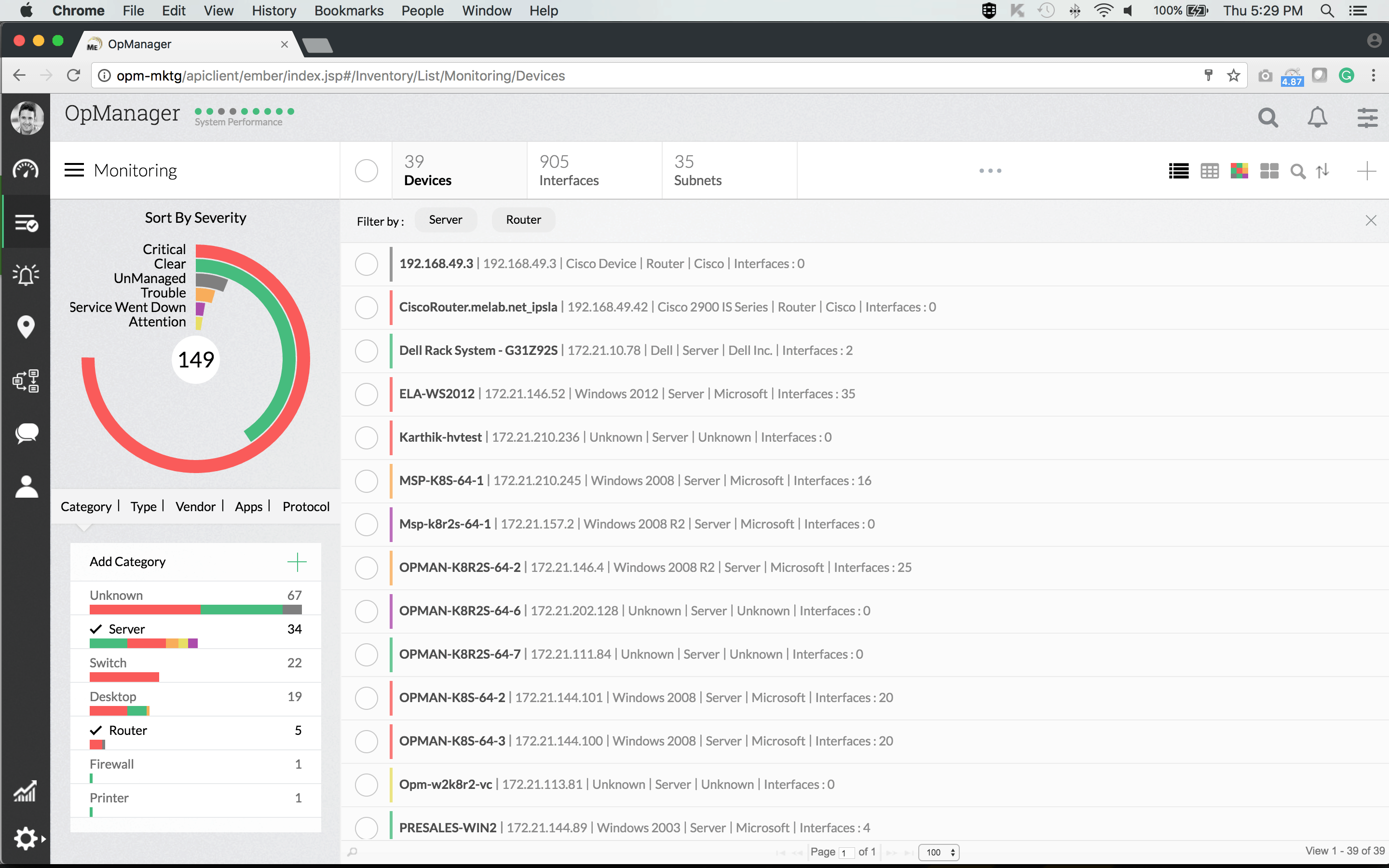
Alarmerende ind OpManager er en anden af produktets styrker. Der er et komplet komplement af tærskelbaserede alarmer, der hjælper med at registrere, identificere og fejlfinde netværksproblemer. Der kan indstilles flere tærskler med forskellige underretninger for hver præstationsmetrik.
Hvis du vil prøve ManageEngine OpManager, få den gratis version. Det er ikke en tidsbegrænset prøveversion. Det er i stedet for funktionsbegrænset. Det lader dig for eksempel ikke overvåge mere end ti enheder. Selvom dette muligvis er tilstrækkeligt til testformål, passer det kun de mindste netværk. For flere enheder kan du vælge mellem Vigtig eller den Enterprise planer. Den første giver dig mulighed for at overvåge op til 1 000 knudepunkter, mens den anden går op til 10 000. Prisoplysninger er tilgængelige ved at kontakte ManageEngineSalg.
3. PRTG Network Monitor
Det PRTG Network Monitor fra Paessler AG er et agentfrit netværksovervågningssystem. Paessler hævder, at PRTG Network Monitor kan indstilles på et par minutter. Vores erfaring viser, at det kan tage lidt mere end det, men at det stadig er meget let og hurtigt takket være en auto-opdagelsesfunktion, der scanner dit netværk, finder enheder og automatisk tilføjer dem. Værktøjet bruger en kombination af Ping, SNMP, WMI, NetFlow, jFlow, sFlow, men kan også kommunikere via DICOM eller RESTful API.
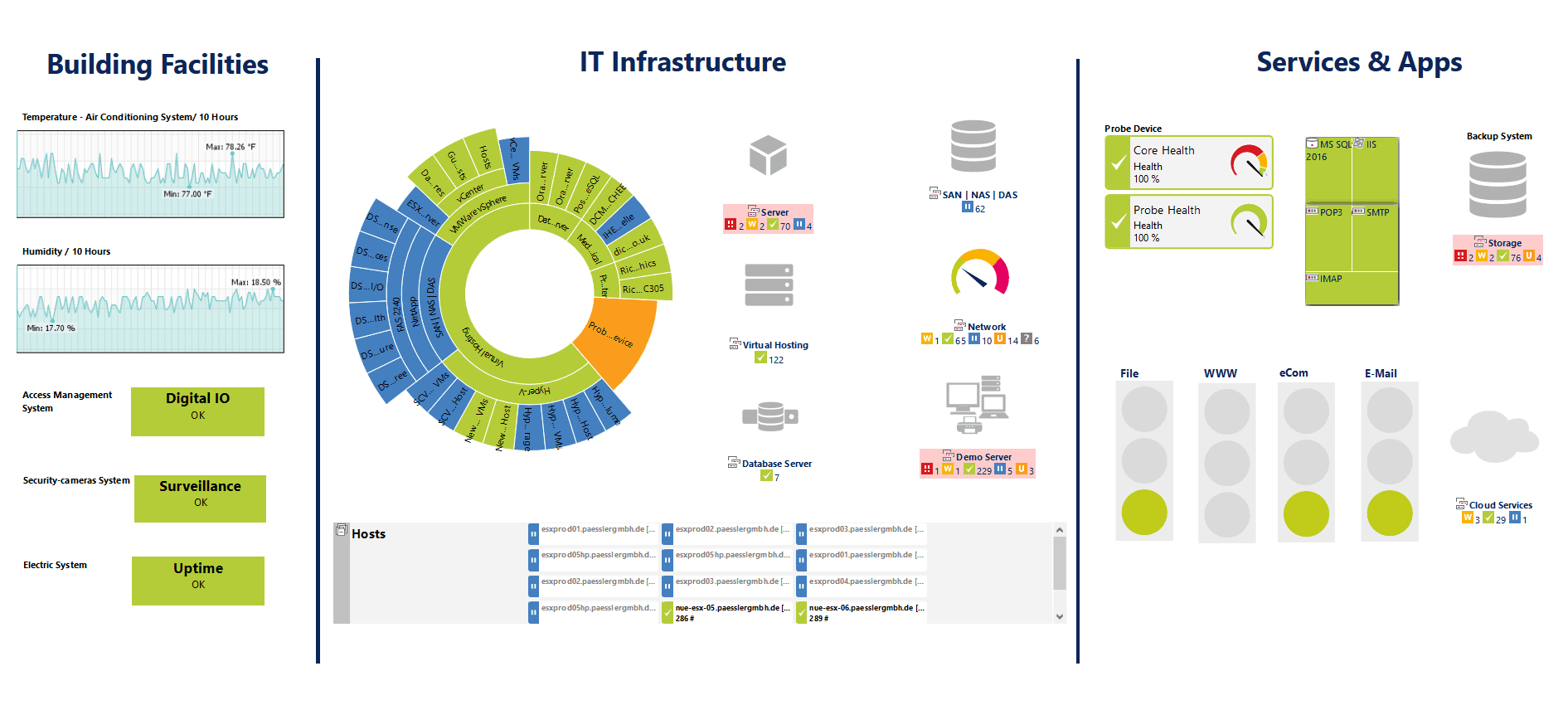
En af styrkerne ved PRTG Network Monitor er dens sensorbaserede arkitektur. Du kan tænke på sensorer som tilføjelser til produktet bortset fra at de allerede er inkluderet og ikke behøver at tilføjes. Der er tilføjelser til stort set alt. For eksempel er der HTTP, SMTP / POP3 (e-mail) applikationssensorer. Der er også hardwarespecifikke sensorer til switches, routere og servere. I alt er der over 200 forskellige foruddefinerede sensorer, der henter statistikker såsom responstid, processor, hukommelse, databaseinformation, temperatur eller systemstatus fra de overvågede enheder.
Det PRTG Network Monitor tilbyder et udvalg af brugergrænseflader. Den primære er en Ajax-baseret webgrænseflade. Der er også en Windows-konsol samt mobile apps til Android og iOS. En dejlig funktion ved mobilapps er, at de kan bruge push-anmeldelse af alle advarsler, der er udløst fra PRTG. Flere standardmeddelelser om SMS eller e-mail er også tilgængelige. Selvom serveren kun kører på Windows, kan den administreres fra enhver enhed med en Ajax-kompatibel browser.
Det PRTG Network Monitor tilbydes i to versioner. Der er en gratis version, der er fuldt udstyret, men som begrænser din overvågningsevne til 100 sensorer. Bemærk, at hver overvåget parameter tæller som en sensor, og for eksempel monitor 24-grænseflader på en netværksafbryder bruger 24 sensorer. Hvis du har brug for mere end 100 sensorer, skal du købe en licens. Deres priser starter ved $ 1 600 for 500 sensorer. Du kan også få en gratis, sensor-ubegrænset og fuldt udstyret 30-dages prøveversion.









Kommentarer