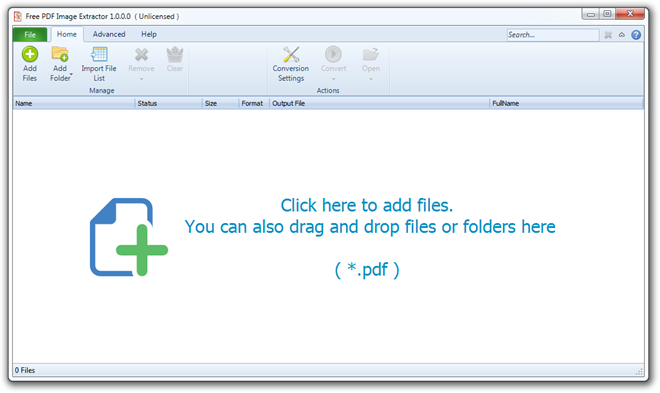
多くのPDFリーダーにはテキストをコピーする機能があります画像とともに、リッチテキストをドキュメントに貼り付けることができます。しかし、数百の画像を含むPDF文書を扱う場合、PDFファイルからすべての画像を手動で抽出すると、面倒な作業になるだけでなく、時間もかかります。 Fusion PDF Image Extractor 努力を軽減するために開発され、重要なのは、定義されたローカルの場所でPDFドキュメントから画像を収集するのに必要な時間です。指定されたPDFドキュメントからすべての画像を抽出し、指定されたフォルダーに保存するための小さなオープンソースアプリケーションです。また、iTextSharpライブラリとGhostScriptスクリプトを使用してPDFページ全体を画像に処理し、ユーザーがページ全体を画像として抽出できるようにします。
デフォルトでは、GhostScriptスクリプトを使用してPDFドキュメントページを画像に変換しませんが、有効にすることができます PDF全体のページ変換にGhostscriptを使用 ページを画像に変換するオプション。画像抽出プロセスを開始するには、出力ファイルが後に続くPDFファイルを指定するだけです。

プロセスが終了すると、画像抽出操作中に処理されたページ数が表示されます。

出力場所で選択したPDFファイルから抽出した画像を確認します。 GhostScriptオプションを有効にした場合、すべてのページが画像として抽出されます。

Fusion PDF Image Extractorは多くのことを節約しますPDFファイルから画像を手動で抽出するのに費やした時間。それでも、画像を抽出するページを選択するオプションがあれば、もっとよかったでしょう。
Fusion PDF Image Extractorのダウンロード







コメント