Tinklo vėlavimas dažnai yra priešas numeris vienastinklo administratoriai. Atrodo, kad jis visur šliaužia ir visada tave trenkia, kai tau to mažiausiai reikia. Ir vėl, greičiausiai, jums to niekada nereikia. Vėlavimas gali būti toks, kad jūsų tinklas tampa beveik nenaudojamas. Taigi, ką galima padaryti dėl to? Pirmas žingsnis yra atrasti vėlavimus. Tada turite tai išmatuoti ir surasti. Tik tada galėsite ką nors padaryti išspręsdami. Norėdami jums padėti, mes sudarėme tinklo latentinio tikrinimo įrankių, kurie gali padėti aptikti ir įvertinti vėlavimo problemas, sąrašą.

Prieš pradėdami, pamėginsime paaiškinti kądelsimas yra ir kas tai lemia. Tai padės geriau suprasti, kaip gali padėti skirtingos priemonės. Taip pat išnagrinėsime delsos svarbą ir kaip tai veikia tinklo naudojimą. Tada pažiūrėsime, kaip išmatuoti tinklo delsą. Ir todėl nenaudinga surasti ir išmatuoti delsos, jei nieko nebus imamasi, mes taip pat aptarsime tinklo delsos mažinimą. Tada būsime pasirengę pateikti geriausių tinklo delsos tikrinimo įrankių sąrašą. Bet pamatysite, kad tai ne tik sąrašas, bet ir trumpai apžvelgiame kiekvieną iš įrankių.
Kas yra tinklo delsos?
Vienu sakiniu tinklo latentinis matas yralaikas, per kurį duomenų paketas gali patekti iš savo šaltinio į savo tikslą. Idealiame pasaulyje nebūtų jokio latentiškumo. Bet iš tikrųjų tokių visada bus. Ir nors vėlavimas neišvengiamas, visada reikia įsitikinti, kad jis nėra toks svarbus, kad pradėtų paveikti normalų tinklo veikimą.
Prie vėlavimo prisideda keli veiksniai. Pirma, yra dauginimosi laikas. Nors tinklai yra greiti ir bitai keliauja šviesos greičiu, pasiekti tikslą vis tiek reikia laiko. Ir kuo ilgesnis kelias, tuo daugiau laiko reikės. Dėl šios priežasties latencija tarp dviejų kompiuterių, esančių tūkstančius mylių vienas nuo kito, paprastai bus didesnė nei tarp kompiuterių, esančių toje pačioje patalpoje.
Kitas prisidedantis veiksnys yra vadinamasperdavimo uždelsimas. Tai yra vėlavimas, kurį gali pateikti pati laikmena. Tai taip pat lemia duomenų paketų dydis. Didesnės pakuotės bus vėlesnės, nes jas pristatyti reikės daugiau laiko.
Maršrutizatoriai ir kiti apdorojimo vėlavimai taip pat yra atinklo delsos šaltinis. Net ir vos naudojamose schemose, kur nėra eilės, kiekvienas maršrutizatorius turi manipuliuoti duomenimis. Pvz., TTL antraštės lauką reikia sumažinti.
Tiesą sakant, dar daugiau vėlavimų gali turėti įtakos duomenimsperdavimas. Galime galvoti apie vėlavimą į eilę, kai duomenys negali būti siunčiami iš karto, arba saugojimo atidėjimą, kai jie turi būti talpykloje į diską ar atmintį, o po to nuskaityti.
Latencijos matavimas
Išmatuoti delsą gali būti sudėtingiauatrodo. Tai ypač pasakytina matuojant latenciją tarp labai tolimų taškų. Tam yra kelios priežastys, tačiau dažniausiai taip yra todėl, kad net ir didžiulis delsos laikas yra palyginti trumpas - kelių tūkstantųjų sekundės dalis. Negalite iš tikrųjų paskambinti savo draugui kitame gale ir pasakyti jam „Gerai, aš siunčiu tau paketą, pasakyk man, kai jis atvyks“ ir išmatuoti vėlavimą. Tikėtina, kad paketas atvyks dar prieš jums net nebaigus kalbėti. Pamirškite skirti laiką.
Paprastai latencija matuojama siunčiantpaketą, kuris grąžinamas siuntėjui, ir matuojant laiką, kurio reikia atsakymui grįžti. Būtent šis kelionė pirmyn ir atgal yra laikoma latencija. Šis vertinimo metodas turi keletą trūkumų. Pvz., Jei grįžimo kelias yra kitoks, latentinis skaičius nepasakys, kuris iš pirmyn ar atgal nukreiptų kelių turi vėlavimą.
Kita galima problema yra ta, kadpaketai, naudojami latencijai matuoti - paprastai ICMP užklausos ir atsakymai - tinklo įrenginiuose ne visada yra traktuojami tokiu pat prioritetu kaip kai kurių kitų tinklo srautų.
Kodėl latentinis laikotarpis yra svarbus?
Lengvas atsakymas yra akivaizdus: nes kai vėlavimas tampa per didelis, tai gali paveikti tinklų tinkamumą. Taigi svarbu ne pats latentinis laikotarpis, o stebėjimas. Neįprastai aukštas ar didesnis nei įprasta vėlavimas dažnai yra ženklas, kad tinkle ar tinkle yra kažkas ne taip. Dažniausiai tai bus spūsčių padarinys. Tinklai yra tarsi greitkeliai, o kai eismas per didelis, viskas sulėtėja ir jūs gaunate ilgą vėlavimą.
Bet išmatuotas delsimas ne visada rodotinklo problema. Kadangi latenciją dažniausiai matuojame matuojant važiavimo į abi puses laiką, kitas latencijos šaltinis galėtų būti tolimiausias įrenginys. Jei tas įrenginys labai užsiėmęs daro bet ką, ką jis turi padaryti, jis gali nereaguoti iškart į ICMP užklausą, kurią gavo iš testavimo kompiuterio. Kai tai atsitiks, jis bus suvokiamas kaip tinklo latentinis laikotarpis, tačiau iš tikrųjų tai neturi nieko bendra su tinklu, o jūsų delsos matavimas jums to neduos.
Panašiai vartotojai galėtų tai patirtineturi nieko bendra su tinklu. Taikomosios programos latentinis laikotarpis yra galbūt toks pat įprastas kaip tinklo delsos. Kai serveriai perkraunami, pradedate reaguoti lėčiau. Kaip tinklai, kai jie tampa perpildyti. Tačiau serverių ir programų vėlavimas šiandien tikrai nėra tema.
Sumažinti tinklo delsą
Tai yra vienas (erzinantis) dalykas, kai patiriate vėlavimąir tai yra kitas dalykas, kurį reikia išmatuoti, tačiau koks jis geras, jei nerandate būdo jį sumažinti. Tai padaryti galima keliais būdais. Trumpai tariant, kaip nustatyti ilgą delsą, priklauso nuo to, kas jį sukelia. Kadangi dažniausia delsos priežastis yra per didelis tinklo panaudojimas, pažiūrėkime, ką galima padaryti dėl to.
Tinklo grandinės nėra neribotos ir kadaper daug išnaudojami, susidaro spūstys ir vartotojai patiria didelį vėlavimą. Jis veikia lygiai taip pat kaip greitkelių eismas. Tai ypač pasakytina apie WAN grandines, kurios dažnai turi labai ribotą pralaidumą.
Taigi, norint sumažinti delsą, geriausia būtų - galėtumėteatspėjote - norėdami sumažinti tinklo naudojimą. Bet, žinoma, ne visada tai įmanoma. Štai kur yra tinklo optimizavimas. Galėtume parašyti visą straipsnį apie WAN optimizavimą. Tiesą sakant, mes neseniai tai padarėme. Yra daugybė įrankių, kuriuos galite naudoti atlikdami šią užduotį.
Geriausi delsos matavimo įrankiai
Kaip mes dabar žinome, pirmiausia išspręskite delsos problemasreikia jį išmatuoti ir nustatyti, iš kur jis ateina. Čia gali padėti įrankiai, kuriuos ketiname atskleisti. Kai kurie tiesiog išmatuos delsą, o kiti padės tai tiksliai nustatyti. Kiti vis dar matuoja pralaidumo naudojimą, o tai gali padėti, nes mes žinome, kad per didelis išnaudojimas yra pagrindinė didelio vėlavimo priežastis. Įrankiai yra sugrupuoti ne pagal tipą, o pagal tipą.
1 - „SolarWinds“ tinklo našumo monitorius (NEMOKAMAS bandymas)
„SolarWinds“ yra vienas žinomiausių „tinklo administravimo įrankiai. Bendrovė gyvuoja per amžius ir taip pat garsėja daugybe nemokamų įrankių, kurių kiekvienas patenkina specifinį tinklo administratorių poreikį. Kai kurie nemokami įrankiai buvo apžvelgti šiuose puslapiuose, kai aptarėme geriausius TFTP serverius iš geriausių „syslog“ serverių.
„SolarWinds“ tinklo našumo monitorius arbaNPM yra pavyzdinis „SolarWind“ produktas. Be abejo, viena geriausių SNMP pralaidumo stebėjimo priemonių, joje yra tiek daug funkcijų, kad apie tai galėtume kalbėti valandų valandas. Labiausiai tikėtinas įrankio pranašumas - jo paprastumas. Tačiau šis paprastumas nėra lankstumo kaina. Prietaisų skydelius, rodinius, diagramas ir ataskaitas galima visiškai pritaikyti pagal jūsų pageidavimus ar poreikius. Įrankį galima nustatyti per kelias minutes ir jis gali būti nuo mažiausių iki didžiausių tinklų, turinčių tūkstančius prietaisų.
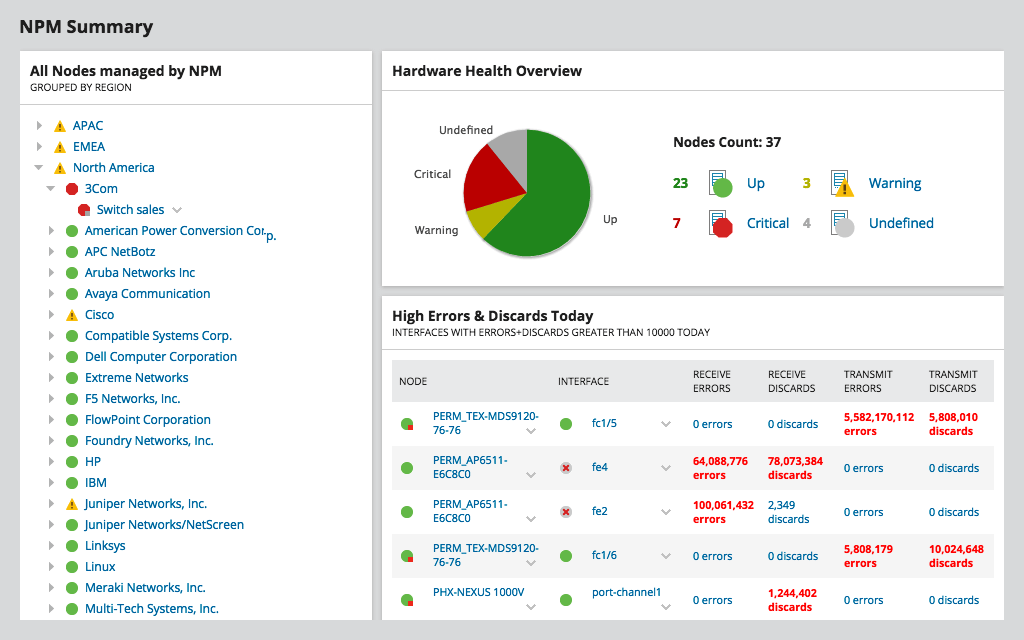
NPM tiesiogiai nematuos tinklo delsos,nors. Bet suteiksite išsamios informacijos apie kiekvienos tinklo dalies pralaidumo naudojimą, tai leis greitai nustatyti gedimų vietas, kur spūstys gali būti didelio vėlavimo priežastis.
NPM naudoja SNMP periodiškai apklausti jūsų įrenginiusir nuskaityti jų sąsajų skaitiklius, apskaičiuoti pralaidumo naudojimą ir parodyti juos kaip grafikus. Norint sukonfigūruoti įrankį reikia tik nurodyti įrenginio IP adresą ir bendruomenės eilutę. Išplėstinės funkcijos leidžia jums sukurti tinklo žemėlapius ir parodyti kritinį kelią tarp dviejų įrenginių, o tai yra puiki funkcija, kai reikia pašalinti vėlavimo triktis.
Tinklo našumo monitoriaus kaina prasideda nuo 2 955 USD. Jei norėtumėte išbandyti įrankį prieš jį įsigydami, galimas visas 30 dienų išbandymas.
2 - „SolarWinds“ „NetFlow“ srauto analizatorius (NEMOKAMAS bandymas)
Kitas puikus „SolarWinds“ produktas„NetFlow“ srauto analizatorius administratoriams gali suteikti išsamesnį tinklo srauto vaizdą. Tai ne tik parodys jūsų panaudojimą ir galimą delsą, bet ir parodys, kur tai vyksta ir dažnai tai lemia. Įrankis pateikia išsamią informaciją apie stebimą srautą. Pavyzdžiui, įrankis leis jums sužinoti, kokio tipo srautas ar koks vartotojas sunaudoja didžiausią pralaidumą. „NetFlow“ srauto analizatoriaus prietaisų skydelyje yra keletas galimų naudingų rodinių, tokių kaip geriausios programos, geriausi protokolai ar geriausi pranešėjai.
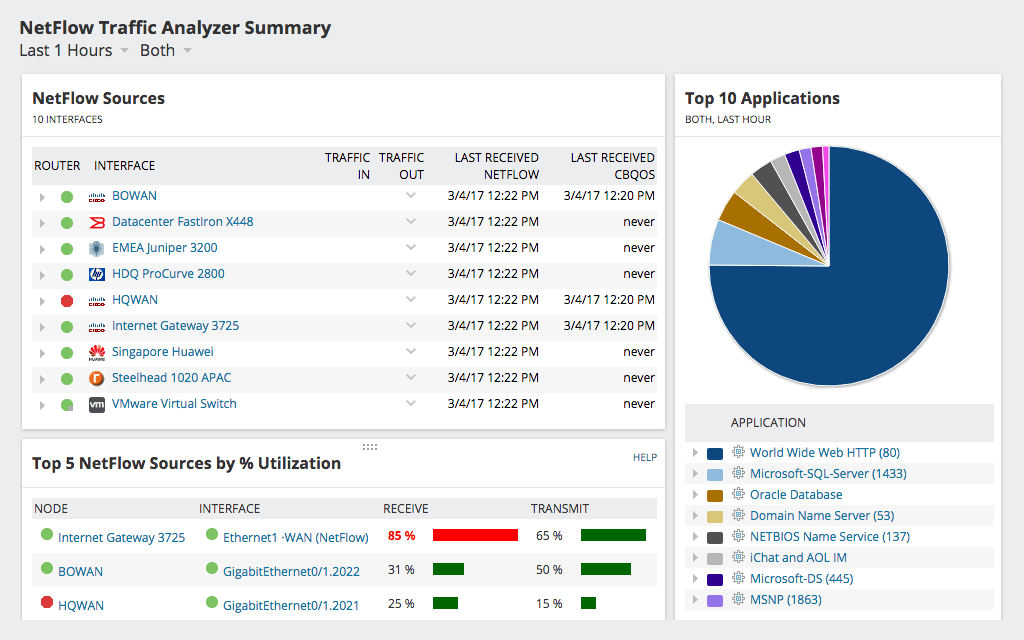
„SolarWinds NetFlow“ srauto analizatorius naudoja„NetFlow“ protokolas, skirtas rinkti išsamią naudojimo informaciją iš tinklo įrenginių. Iš pradžių „Cisco“ sukurtas „NetFlow“ protokolas leidžia įrenginiams siųsti išsamią informaciją apie kiekvieną tinklo „pokalbį“ arba srautą „NetFlow“ kolektoriui ir analizatoriui, tokiam kaip „NetFlow“ srauto analizatorius. Šioje informacijoje yra keli elementai, kurie gali būti naudojami srautui analizuoti. Daugelis gamintojų, išskyrus „Cisco“, taip pat į savo įrangą įtraukia „NetFlow“ funkcionalumą ar jo atitikmenį, kartais pavadindami jį kitu vardu. Neseniai IETF standartizavo „NetFlow“ protokolą kaip IPFIX arba IP srauto informacijos mainus. „SolarWinds NetFlow“ srauto analizatorius veiks su visais protokolo variantais, todėl bus puikus pasirinkimas.
„SolarWinds NetFlow“ srauto analizatorius yrapapildomas modulis, kuris įdiegiamas tinklo našumo monitoriaus viršuje. Kainos prasideda nuo 1 915 USD ir skiriasi priklausomai nuo priimančiųjų skaičiaus. Kaip ir daugelyje mokamų „SolarWinds“ produktų, siūlomas nemokamas bandomasis produktas.
3 - Paessler PRTG
„Paessler Router Traffic Grapher“ arba PRTG yradar viena pralaidumo stebėjimo priemonė. Tai yra vienas iš lengviausių ir greičiausių. „Paessler“ tvirtina, kad jūs tikrai galite sukurti ir paleisti per kelias minutes, o produkto nustatymas neužima daug laiko, nors ir šiek tiek daugiau, nei reikalaujama. Produktas turi automatinio aptikimo funkciją, kuri reiškia, kad jis nuskaitys jūsų tinklą ir automatiškai pridės rastus komponentus.
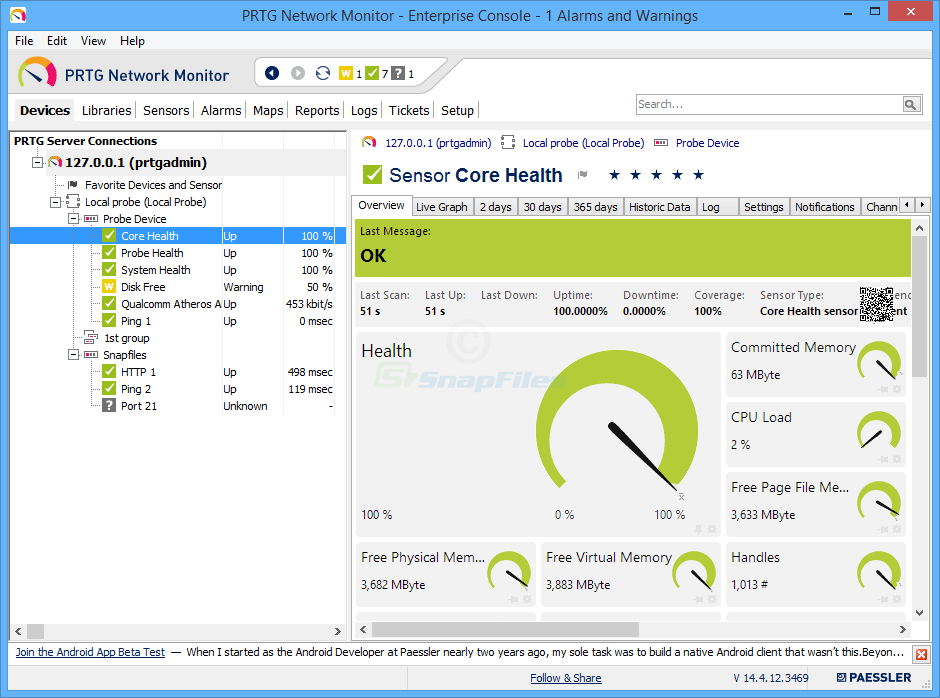
PRTG yra standartinis su keliomis vartotojo sąsajomis,leidžianti išsirinkti sau tinkamiausią. Yra sava „Windows“ konsolės programa, taip pat yra „Ajax“ pagrįsta žiniatinklio sąsaja ir yra mobiliųjų programų, skirtų „Android“ ir „iOS“. Ir tai puikiai išnaudoja kiekvienos platformos galimybes. Pvz., Programos mobiliesiems leis jums pasiekti bet kurią įrenginio informaciją, tiesiog nuskaitydami ant jo pritvirtintą QR kodo etiketę. Žinoma, „Windows“ konsolė leis jums spausdinti tas etiketes.
PRTG naudoja savo technologijasstebėjimas. Bus naudojamas SNMP stebėjimas, taip pat WMI „Windows“ įrenginiams ir „NetFlow“ ir „Sflow“ - dvi panašios, bet konkuruojančios srautų analizės technologijos. Įrankis turi kelis jutiklius, specialiai sukurtus matuoti latenciją. Yra „QoS“ jutiklis, kuris išmatuos važiavimo pirmyn ir atgal laiką, „Cisco IP SLA“ jutiklis ir „Ping“ jutiklis.
4 - „ManageEngine NetFlow An“alyzeris
„ManageEngine NetFlow“ analizatorius yra dar vienas„NetFlow“ pagrindu sukurtas stebėjimo įrankis, turintis keletą pažangių latencijos stebėjimo funkcijų. Įrankis pateikia išsamų tinklo naudojimo ir srauto modelių vaizdą. Jo internetinė vartotojo sąsaja leis jums peržiūrėti srautą pagal programas, pokalbius, protokolus ir dar daugiau. Išsami įrankio informacijos suvestinė yra viena geriausių jo savybių. Tai siūlo keletą geriausių universalumų ir leis įtraukti visus norimus duomenis. Ir keliaujantiems administratoriams yra mobiliųjų programų.
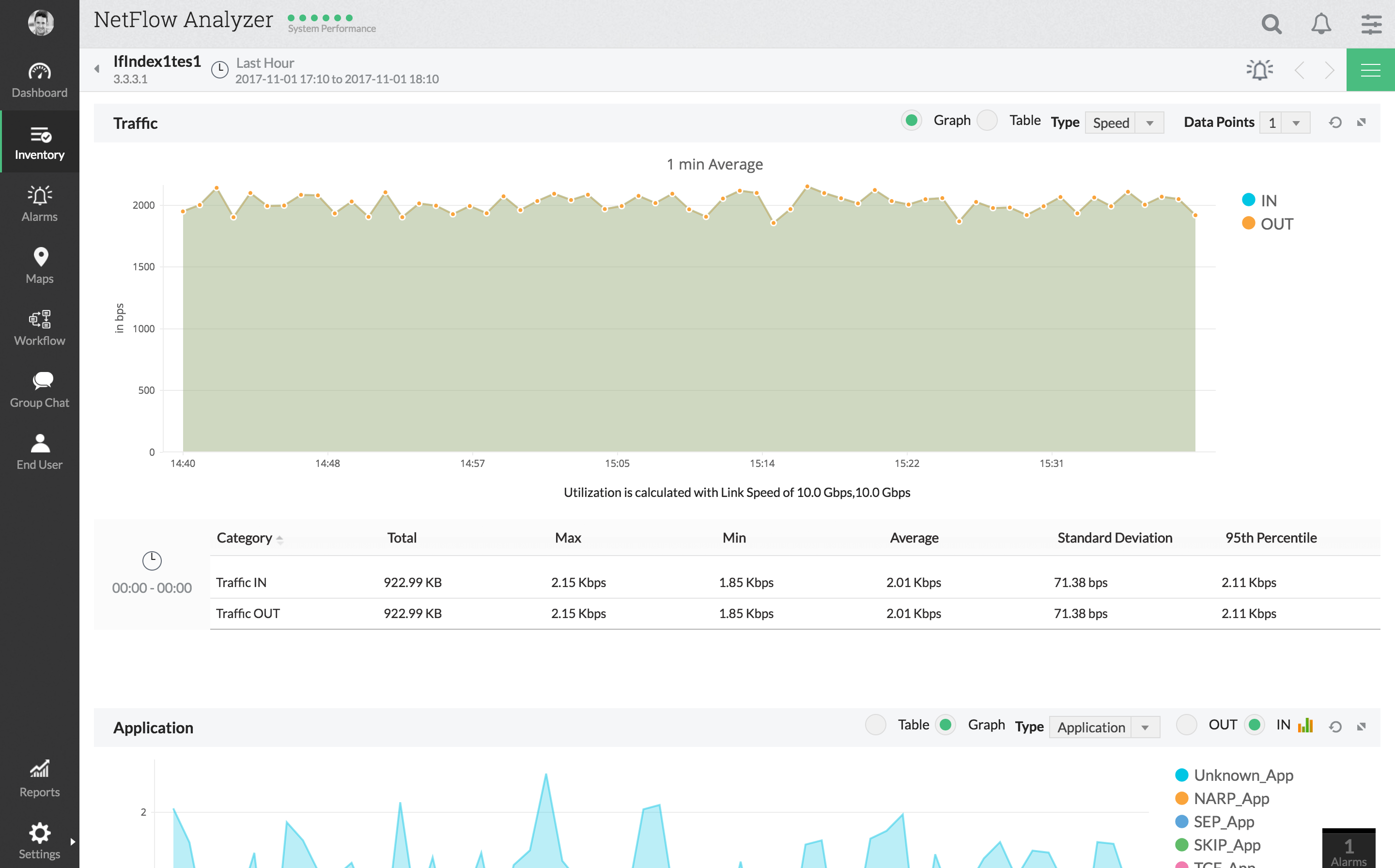
„ManageEngine NetFlow Analyzer“ palaikokeletas srautų technologijų, įskaitant „NetFlow“, IPFIX, „J-flow“, „NetStream“ ir dar keletą. Kaip privalumas, taip pat puiki integracija su „Cisco“ įrenginiais, palaikant srauto formavimo ir (arba) „QoS“ politikos pritaikymą tiesiai iš įrankio.
Latencijos matavimui šis įrankis turi „WAN Round Trip Time“ (RTT) monitorių, leidžiantį stebėti WAN prieinamumą, vėlavimą ir paslaugų kokybę.
5 - „PingPlotter“
Nepaisant klaidinančio pavadinimo, „PingPlotter“ yraiš tikrųjų grafinė „Traceroute“ programinė įranga, kuri gali padėti išspręsti tinklo problemas. Šis diagnostikos įrankis nubraižo vėlavimą ir paketų praradimą tarp jūsų kompiuterio ir taikinio. Tai leidžia jums vizualizuoti informaciją, pagreitina trikčių šalinimo procesą ir gali padėti sukurti bylą, jei jums reikia įtikinti, kad jų pabaigoje yra problema.
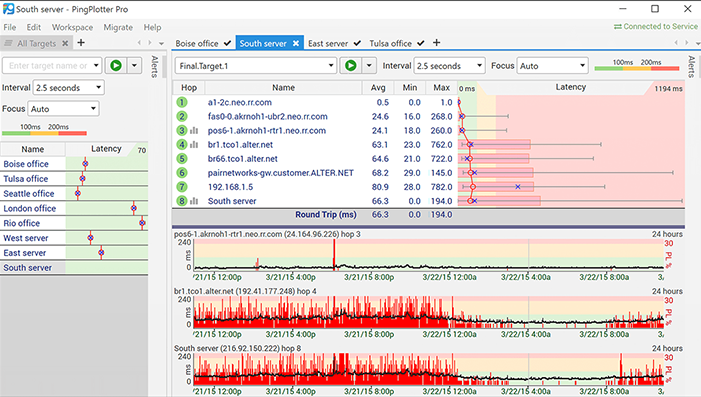
„PingPlotter“ grafiką tinklo veikimo grafikas rodo kiekvienameperšokite tarp kompiuterio, kuriame jį naudojate, ir tikslinės svetainės, serverio ar įrenginio. Įrankis patikrins kelią į bet kokį prie tinklo pasiekiamą įrenginį. Tai rodo, kur atsitinka vėlavimas, sutaupydamas daug diagnostikos laiko.
Nors naudinga turėti našumo statistiką,jie tik jums sako, kad tinklas nepavyko arba nepavyko per bandymą ir kur jis buvo. „PingPlotter“ turi naudingą laiko juostos funkciją, kuri suteikia gilesnį supratimo lygį tiksliai parodant problemas. Tai leidžia atskirti nuolatinį gedimą viso testo metu ir trumpą sunkų nesėkmės periodą. Tai taip pat gali padėti susieti nesėkmę su kitais tuo pat metu vykstančiais įvykiais.
6 - „MultiPing“
„MultiPing“ yra dar vienas produktas, turintis šiek tiekklaidinantis vardas. Nors „MultiPing“ pirmiausia naudoja „Ping“ savo žygdarbiui atlikti, ji iš tikrųjų yra stebėjimo sistema, šiek tiek panaši į „SolarWinds“ NPM. Žinoma, naudojant „Ping“, o ne SNMP reiškia, kad jūsų gaunama informacija yra labai skirtinga. Nesitikėkite, kad naudojant šį įrankį bus išnaudotas pralaidumas. Vienas dalykas, kurį pamatysite, yra delsimas. Kaip ir juostos pločio monitoriai bėgant laikui nubraižys juostos pločio grafikus, šis taip pat parodys latenciją per tam tikrą laiką.
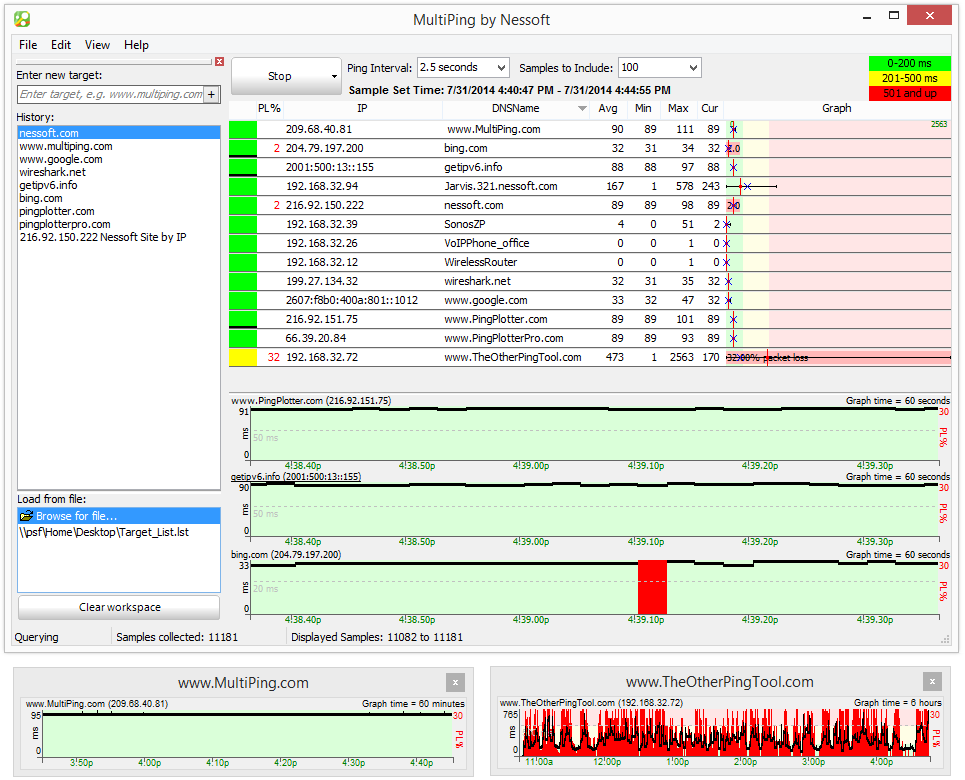
„MultiPing“ parodys paketų praradimą procentaistaip pat minimalų, vidutinį ir maksimalų delsą. Jis turi automatinį aptikimą, todėl jo sąranka yra labai lengva užduotis. Produkto vartotojo sąsaja gali būti sukonfigūruota pagal jūsų skonį įdėjus įvairius komponentus, kaip jums atrodo tinkama. Sistema taip pat turi įspėjimą, kuris gali pranešti, kai parametrai išeina iš diapazono. Be įspėjimų, programas galima paleisti ir dėl įspėjimų.
7 - „Ping“
Jums nieko nereikia atsisiųsti ar įdiegtivis dėlto išbandykite latenciją. „Ping“ yra komanda, kuri įmontuota į moderniausias operacines sistemas. Trumpai tariant, „Ping“ siunčia ICMP aidų užklausų serijas tiksliniam IP adresui ir laukia, kol ji atsakys pateikdama atitinkamus ICMP atsakymus į aidą. Vėlavimas tarp prašymo ir atsakymo yra vadinamas važiavimu pirmyn ir atgal, kuris taip pat vadinamas vėlavimu. Kai nesulaukia atsakymo į vieną iš savo užklausų, naudingumo tarnyba daro prielaidą, kad arba užklausa, arba atsakymas dingo tranzito metu, ir kaupia informaciją apie paketų praradimą, kuri rodoma, kai komanda baigia vykdyti.
8 - „Traceroute“ (arba „Tracert“)
Panašiai yra „Traceroute“ arba „Tracert“, jei jūs atvykstateiš „Windows“ pasaulio, taip pat gali būti naudojamas latencijos testavimo tikslams. Tai dar viena komanda, įmontuota daugumoje operacinių sistemų. Jis naudoja to paties tipo ICMP užklausas ir atsakymus kaip ir „Ping“, tačiau tai daro tokiu būdu, kuris leidžia individualiai išbandyti kiekvieno tinklo segmento reakcijos laiką arba latenciją kelyje. Tai netgi geriau nei „Ping“, nes tai gali suteikti gana gerą idėją apie tai, kur vyksta didžiausia delsos trukmė. Taigi šis įrankis gali ne tik įvertinti, bet ir nustatyti latenciją.









Komentarai