Tīkla latentums bieži ir ienaidnieks numur vienstīkla administratori. Liekas, ka tas visur rāpo un vienmēr skar tevi, kad tas vismazāk vajadzīgs. Tad atkal, iespējams, jums tas nekad nav vajadzīgs. Latentums var būt tāds, kas padara jūsu tīklu tik tikko izmantojamu. Tātad, ko tajā var darīt? Pirmais solis ir atklāt latentumu. Pēc tam tas jāmēra un jāatrod. Tikai tad jūs varēsit kaut ko darīt, lai to atrisinātu. Lai palīdzētu jums, mēs esam izveidojuši tīkla latentuma pārbaudes rīku sarakstu, kas var palīdzēt atklāt un izmērīt latentuma problēmas.

Pirms darba sākšanas mēs centīsimies izskaidrot, kolatentums ir un kas to izraisa. Tas palīdzēs labāk izprast, kā var palīdzēt dažādi rīki. Mēs arī pārbaudīsim latentuma nozīmi un to, kā tā ietekmē tīkla izmantošanu. Tad mēs apskatīsim, kā mēs varam izmērīt tīkla latentumu. Un tā kā nav jēgas atrast un izmērīt latentumu, ja nekas netiks darīts, mēs apspriedīsim arī tīkla latentuma samazināšanu. Pēc tam mēs būsim gatavi iesniegt labāko tīkla latentuma pārbaudes rīku sarakstu. Bet jūs redzēsit, ka tas nav tikai saraksts, mēs arī īsi pārskatām katru no rīkiem.
Kas ir tīkla latentums?
Vienā teikumā tīkla latentums ir mērauklalaiks, kas nepieciešams datu paketei, lai nokļūtu no avota līdz mērķim. Ideālā pasaulē nebūtu nulles latentuma. Bet patiesībā to vienmēr būs. Un, lai arī latentums ir neizbēgams, vienmēr ir jāpārliecinās, ka tas nav tik svarīgs, ka tas sāk ietekmēt normālu tīkla darbību.
Vairāki faktori veicina latentuma palielināšanos. Pirmkārt, ir pavairošanas laiks. Lai arī tīkli ir ātri un biti pārvietojas gaismas ātrumā, mērķa sasniegšanai joprojām ir vajadzīgs zināms laiks. Un jo garāks ceļš, jo vairāk laika tas prasīs. Šī iemesla dēļ latentums starp diviem datoriem, kas atrodas tūkstošiem jūdžu attālumā viens no otra, parasti ir lielāks nekā starp datoriem tajā pašā telpā.
Tiek saukts vēl viens veicinošais faktorspārraides kavēšanās. Tā ir kavēšanās, ko var ieviest pats medijs. Tas izriet arī no datu pakešu lieluma. Lielākām paciņām būs lielāks latentums, jo to piegāde prasa vairāk laika.
Maršrutētāja un citas apstrādes kavēšanās arī ir atīkla latentuma avots. Pat tik tikko izmantotās shēmās, kur rindu nav, katram maršrutētājam ir jā manipulē ar datiem. Piemēram, TTL galvenes lauks ir jāsamazina.
Faktiski datus var ietekmēt vēl daudz kavējumupārraide. Mēs varam domāt par aizkavēšanos rindā, kas notiek, ja datus nevar nosūtīt nekavējoties, vai glabāšanas aizkavēšanos, kad tie ir jātur kešatmiņā diskā vai atmiņā un pēc tam jāielādē.
Latentuma mērīšana
Latentuma mērīšana var būt daudz sarežģītākaizskatās. Tas jo īpaši attiecas uz mērījumu latentumu starp ļoti attāliem punktiem. Tam ir daži iemesli, bet tas galvenokārt ir saistīts ar faktu, ka pat milzīgais latentums joprojām ir salīdzinoši īss - dažu sekundes tūkstošdaļu attālumā. Jūs nevarat īsti piezvanīt savam draugam otrā galā un pateikt viņam “Labi, es sūtu jums paciņu, pastāstiet man, kad tā pienāk” un izmērīt aizkavēšanos. Iespējams, ka paciņa ieradīsies, pirms jūs pat būsit beidzis runāt. Aizmirstiet par laika grafiku.
Parasti latentumu mēra, nosūtotpakete, kas tiek atgriezta sūtītājam, un tā laika noteikšana, kas nepieciešams atbildes atgriešanai. Tieši šis turp un atpakaļ laiks tiek uzskatīts par latentumu. Šai vērtēšanas metodei ir daži trūkumi. Piemēram, ja atgriešanās ceļš ir atšķirīgs, latentuma skaitlis jums nepateiks, kurš no virzieniem uz priekšu vai atpakaļ ceļiem ir latents.
Vēl viena iespējama problēma ir tā, kalatentuma mērīšanai izmantotās paketes - parasti ICMP pieprasījumus un atbildes - tīkla ierīces ne vienmēr apstrādā ar tādu pašu prioritāti kā dažām citām tīkla trafikām.
Kāpēc latentums ir svarīgs?
Šeit vienkāršā atbilde ir acīmredzama: jo, kad latentums kļūst pārāk augsts, tas var ietekmēt tīklu lietojamību. Tāpēc svarīgi nav latentums pats par sevi, bet gan skatīties. Neparasti augsts vai lielāks nekā parasti latentums bieži ir pazīme, ka tīklā vai tīklā kaut kas nav kārtībā. Lielākoties tās būs sastrēgumu sekas. Tīkli ir kā šosejas, un, kad ir pārāk daudz satiksmes, lietas palēninās, un jūs saņemat lielu latentumu.
Bet izmērīts latentums ne vienmēr ir norādetīkla jautājums. Tā kā mēs parasti mēram latentumu, mērot turp un atpakaļ laiku, vēl viens latentuma avots varētu būt tālā ierīce. Ja šī ierīce ir ļoti aizņemta, darot visu, kas tai jādara, iespējams, tā nekavējoties neatbild uz ICMP pieprasījumu, ko tā saņēmusi no testēšanas resursdatora. Kad tas notiks, tas tiks uztverts kā tīkla latentums, bet tam faktiski nav nekā kopīga ar tīklu, un jūsu latentuma mērīšana jums par to neko neuzzinās.
Līdzīgi lietotāji to varēja izjust latentā laikānav nekā kopīga ar tīklu. Lietojumprogrammu latentums, iespējams, ir tikpat izplatīts kā tīkla latentums. Kad serveri tiek pārslogoti, sāciet reaģēt lēnāk. Tāpat kā tīkli, kad tie ir pārslogoti. Bet serveru un lietojumprogrammu latentums mūsdienās noteikti nav priekšmets.
Tīkla latentuma samazināšana
Tā ir viena (kaitinoša) lieta, kas rodas latentuma dēļun tā ir vēl viena lieta, lai to izmērītu, bet cik labs tas ir, ja neatrodat veidu, kā to samazināt. To var izdarīt vairākos veidos. Īsumā, kā noteikt labu latentumu, ir atkarīgs no tā, kas to izraisa. Un tā kā visizplatītākais latentuma iemesls ir tīkla pārmērīga izmantošana, redzēsim, ko šajā sakarā var izdarīt.
Tīkla shēmas nav neierobežotas un kadpārmērīgi izmantojiet, rodas sastrēgumi un lietotājiem ir liela latentā slodze. Tas darbojas tieši tāpat kā šosejas satiksme. Tas jo īpaši attiecas uz WAN shēmām, kurām bieži ir ļoti ierobežots joslas platums.
Tātad, lai samazinātu latentumu, jums to vajadzētu darītir uzminējuši - lai samazinātu tīkla izmantošanu. Bet, protams, tas ne vienmēr ir iespējams. Šeit nāk tīkla optimizācija. Mēs varētu uzrakstīt veselu rakstu par WAN optimizāciju. Patiesībā mēs nesen to izdarījām. Un ir daudz rīku, kurus varat izmantot, lai palīdzētu veikt šo uzdevumu.
Labākie latentuma mērīšanas rīki
Kā mēs tagad zinām, vispirms jānovērš latentuma problēmastas jāizmēra un jāatrod, no kurienes tas nāk. Šeit var palīdzēt rīki, kurus mēs gatavojamies atklāt. Daži vienkārši izmērīs latentumu, bet citi palīdzēs jums to precīzi noteikt. Citi vēl mēra joslas platuma izmantošanu, kas var palīdzēt, jo mēs zinām, ka liela latentuma galvenais iemesls ir pārmērīga izmantošana. Instrumenti tiek sagrupēti pēc veida, nevis pēc izvēles.
1 - SolarWinds tīkla veiktspējas monitors (Bezmaksas izmēģinājuma versija)
SolarWinds ir viens no pazīstamākajiemtīkla administrēšanas rīki. Uzņēmums darbojas jau vairākus gadus un ir slavens arī ar vairākiem bezmaksas rīkiem, no kuriem katrs pievērš īpašu uzmanību tīkla administratoriem. Šajās lapās tika pārskatīti vairāki bezmaksas rīki, kad mēs apspriedām labākos syslog serveru labākos TFTP serverus.
SolarWinds tīkla veiktspējas monitors vaiNPM ir SolarWind vadošais produkts. Varbūt viens no labākajiem SNMP joslas platuma uzraudzības rīkiem, tas ir aprīkots ar tik daudz funkcijām, ka mēs par to varētu runāt stundām ilgi. Rīka vislabākā priekšrocība, visticamāk, ir tā vienkāršība. Bet šī vienkāršība nenāk par elastības cenu. Informācijas paneļus, skatus, diagrammas un pārskatus var pilnībā pielāgot jūsu vēlmēm vai vajadzībām. Rīku var iestatīt dažu minūšu laikā, un tā mērogs var būt no mazākajiem tīkliem līdz milzīgajiem ar tūkstošiem ierīču.
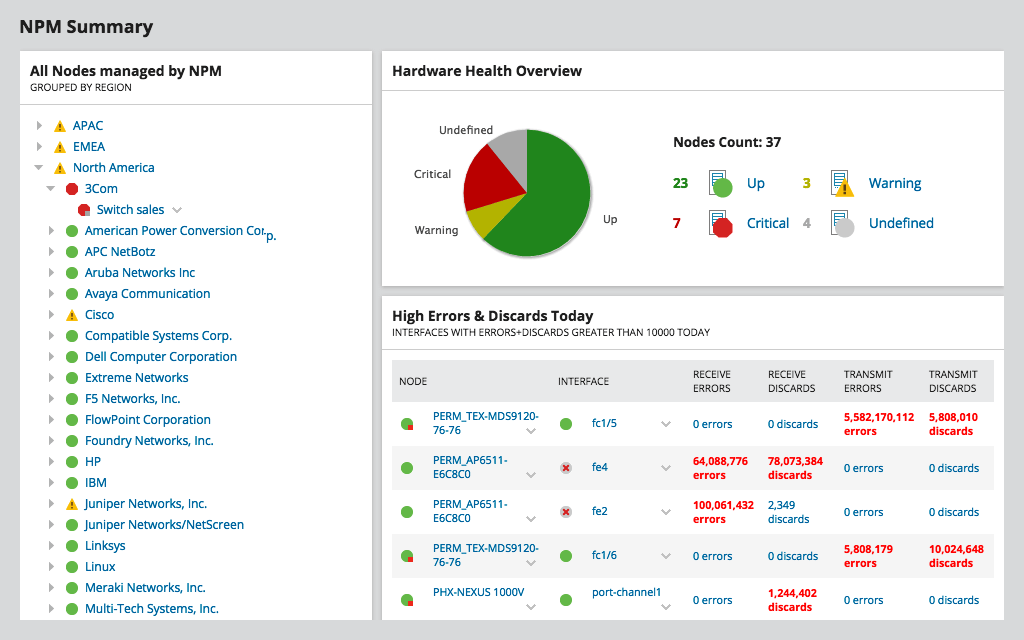
NPM tieši neizmērīs tīkla latentumu,tomēr. Bet, sniedzot jums detalizētu informāciju par joslas platuma izmantošanu visās tīkla daļās, tas ļaus ātri noteikt problēmu vietas, kur sastrēgumi varētu būt liela latentuma cēlonis.
NPM izmanto SNMP, lai periodiski aptaujātu jūsu ierīcesun nolasa to saskarņu skaitītājus, aprēķinot joslas platuma izmantošanu un parādot to kā grafikus. Lai konfigurētu rīku, ir jānorāda tikai ierīces IP adrese un kopienas virkne. Papildu funkcijas ļauj jums izveidot tīkla kartes un parādīt kritisko ceļu starp divām ierīcēm, kas ir lielisks līdzeklis latentuma problēmu novēršanai.
Tīkla veiktspējas monitora cenu noteikšana sākas no 2 955 USD. Ja vēlaties izmēģināt rīku pirms tā iegādes, ir pieejams pilnvērtīgs 30 dienu izmēģinājums.
2 - SolarWinds NetFlow trafika analizators (Bezmaksas izmēģinājuma versija)
Vēl viens lielisks SolarWinds produktsNetFlow trafika analizators administratoriem var sniegt detalizētāku tīkla trafika pārskatu. Tas ne tikai parādīs izmantošanu un potenciālo latentumu, bet arī parādīs, kur tas notiek un bieži to izraisa. Rīks sniedz detalizētu informāciju par novēroto trafiku. Piemēram, rīks ļaus jums uzzināt, kāda veida trafiks vai kāds lietotājs patērē visvairāk joslas platuma. NetFlow trafika analizatora informācijas panelī ir pieejami vairāki noderīgi skati, piemēram, labākās lietojumprogrammas, labākie protokoli vai augstākās sarunas.
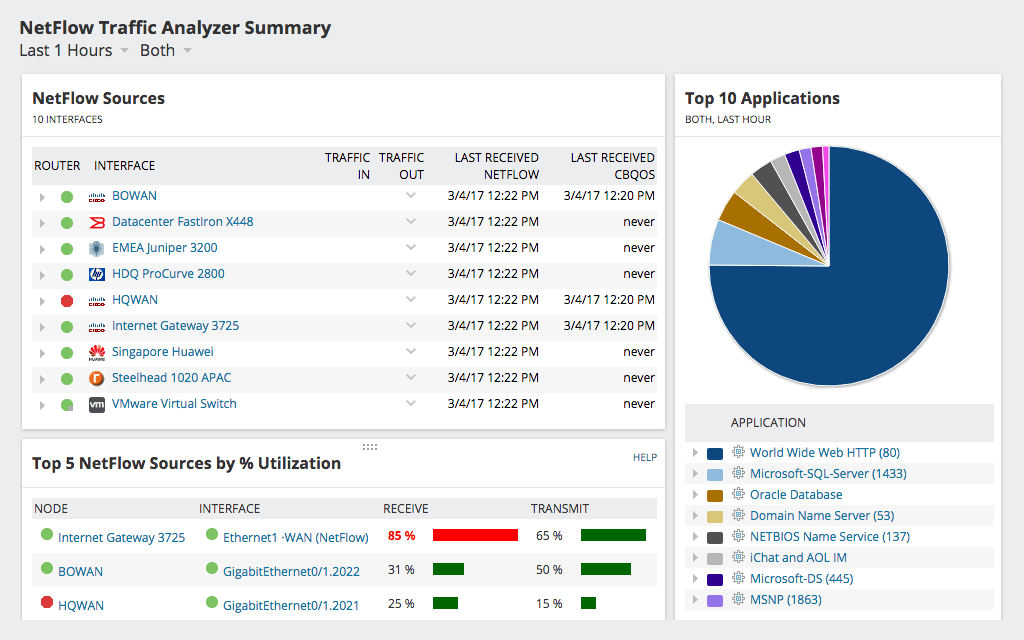
NetFlow trafika analizators izmantoNetFlow protokols, lai apkopotu sīku lietošanas informāciju no tīkla ierīcēm. Sākotnēji Cisco izveidotais protokols NetFlow ļauj ierīcēm sūtīt detalizētu informāciju par katru tīkla “sarunu” vai plūsmu NetFlow kolekcionāram un analizatoram, piemēram, NetFlow trafika analizatoram. Šī informācija satur vairākus elementus, kurus var izmantot, lai analizētu trafiku. Daudzi ražotāji, izņemot Cisco, savās iekārtās iekļauj arī NetFlow funkcionalitāti vai līdzvērtīgu funkciju, dažreiz to saucot par citu vārdu. Nesen IETF NetFlow protokolu standartizēja kā IPFIX vai IP plūsmas informācijas apmaiņu. SolarWinds NetFlow trafika analizators darbosies ar visiem protokola variantiem, padarot to par lielisku izvēli.
SolarWinds NetFlow trafika analizators irpapildu modulis, kas tiek instalēts tīkla veiktspējas monitorā. Cenu sākums ir 1 915 USD un mainās atkarībā no saimnieku skaita. Un tāpat kā vairumam SolarWinds maksas produktu, ir pieejams bezmaksas izmēģinājums.
3 - Paessler PRTG
Paessler Router Traffic Grapher jeb PRTG irvēl viens joslas platuma uzraudzības rīks. Un tas ir viens no vienkāršākajiem un ātrākajiem uzstādīšanas veidiem. Paeslers apgalvo, ka jūs varētu būt gatavs un darboties dažu minūšu laikā un patiesi, produkta iestatīšana neaizņem daudz laika, kaut arī nedaudz vairāk, nekā tiek apgalvots. Produktam ir automātiskās noteikšanas funkcija, kas nozīmē, ka tas skenēs jūsu tīklu un automātiski pievienos atrastos komponentus.
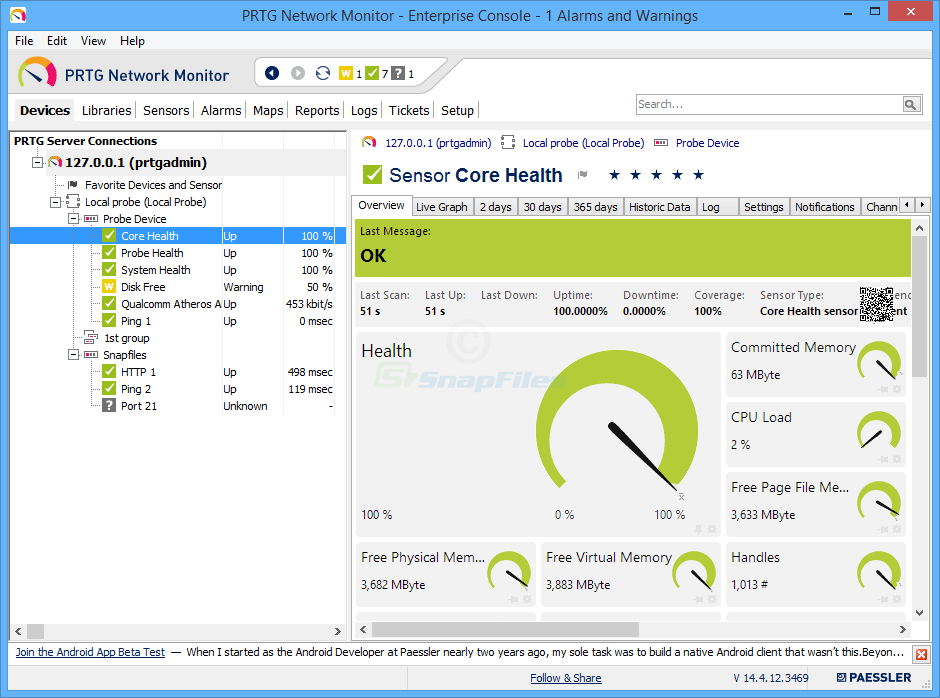
PRTG ietilpst standarta komplektācijā ar vairākām lietotāja saskarnēm,ļaujot izvēlēties sev vispiemērotāko. Ir sava Windows konsoles lietojumprogramma, ir arī Ajax balstīta tīmekļa saskarne, kā arī ir mobilās lietotnes Android un iOS. Un tas lieliski izmanto katras platformas iespējas. Piemēram, mobilās lietotnes ļaus piekļūt jebkurai ierīces informācijai, vienkārši skenējot tai pievienoto QR koda etiķeti. Protams, Windows konsole ļaus jums izdrukāt šīs etiķetes.
PRTG izmanto savu tehnoloģiju apvienojumuuzraudzība. Tas izmantos SNMP uzraudzību, bet arī WMI Windows ierīcēm un NetFlow un Sflow, divas līdzīgas, bet konkurējošas plūsmas analīzes tehnoloģijas. Šim rīkam ir vairāki sensori, kas īpaši izstrādāti latentuma mērīšanai. Ir QoS sensors, kas mērīs brauciena turp un atpakaļ, Cisco IP SLA sensors un Ping sensors.
4 - pārvaldīt programmu NetFlow Analjezers
Vēl viens ir ManageEngine NetFlow analizatorsUz NetFlow balstīts uzraudzības rīks, kas piedāvā dažas uzlabotas latentuma uzraudzības funkcijas. Šis rīks sniedz detalizētu tīkla izmantošanas un trafika modeļa skatu. Tā tīmekļa lietotāja saskarne ļaus jums apskatīt trafiku pēc lietojumprogrammas, pēc sarunas, pēc protokola un daudz ko citu. Rīka visaptverošais informācijas panelis ir viena no labākajām funkcijām. Tas piedāvā dažas no labākajām daudzpusībām un ļaus iekļaut visus vajadzīgos datus. Tiešsaistes administratoriem ir pieejamas mobilās lietotnes.
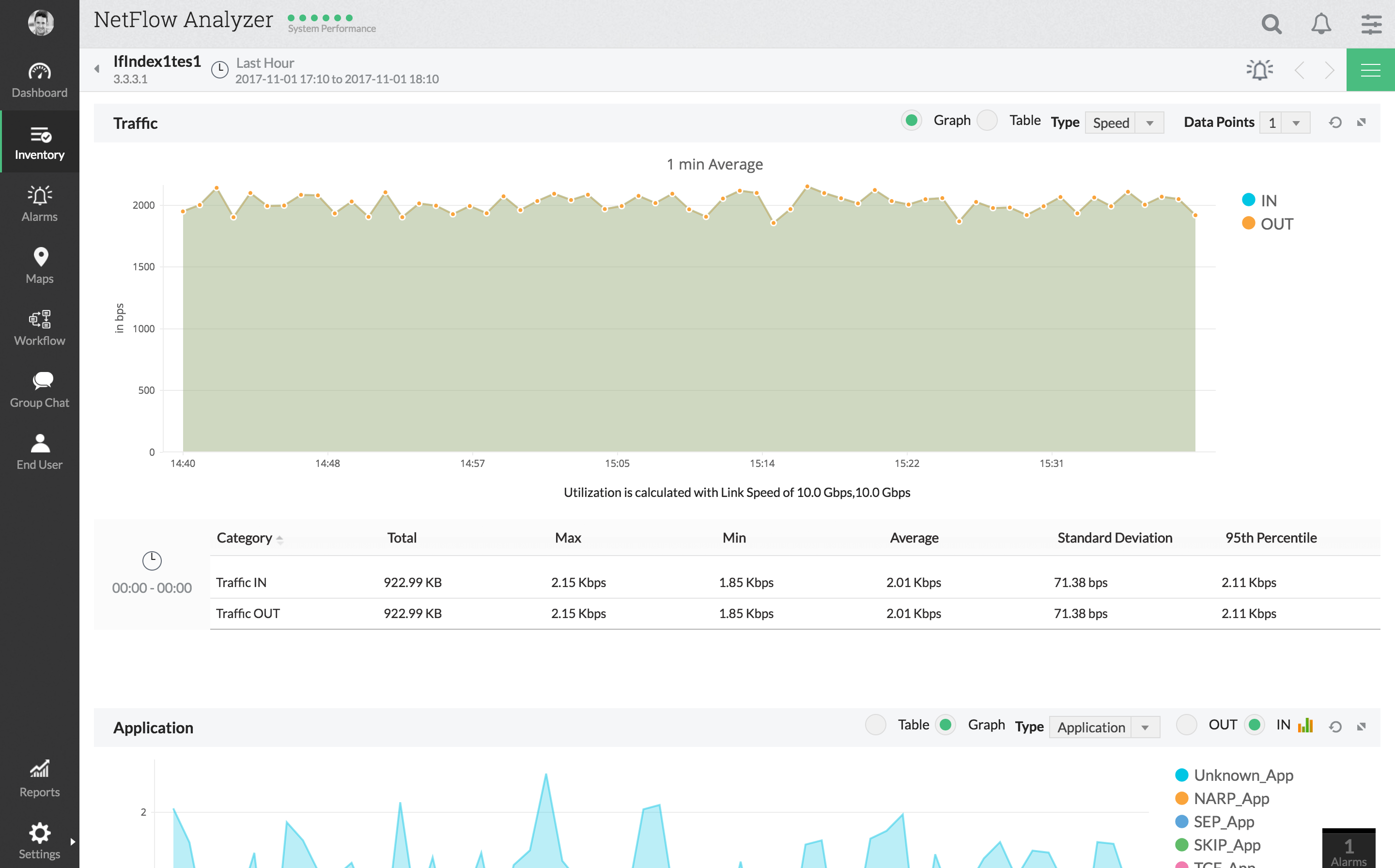
ManageEngine NetFlow Analyzer atbalstavairākas plūsmas tehnoloģijas, ieskaitot NetFlow, IPFIX, J-flow, NetStream un dažas citas. Kā priekšrocība arī šī ir lieliska integrācija ar Cisco ierīcēm ar atbalstu satiksmes veidošanas un / vai QoS politikas pielāgošanai tieši no šī rīka.
Un latentuma mērīšanai šim rīkam ir WAN turp un atpakaļ laika (RTT) monitors, kas ļauj uzraudzīt WAN pieejamību, latentumu un pakalpojuma kvalitāti.
5 - PingPlotter
Neskatoties uz maldinošo nosaukumu, PingPlotter irfaktiski grafiska programmatūra Traceroute, kas var palīdzēt atrisināt tīkla problēmas. Šis diagnostikas rīks attēlo latentumu un pakešu zudumu starp datoru un mērķi. Tas ļauj jums vizualizēt informāciju, paātrina traucējummeklēšanas procesu un var palīdzēt izveidot lietu, ja jums jāpārliecina kāds, kura galā pastāv problēma.
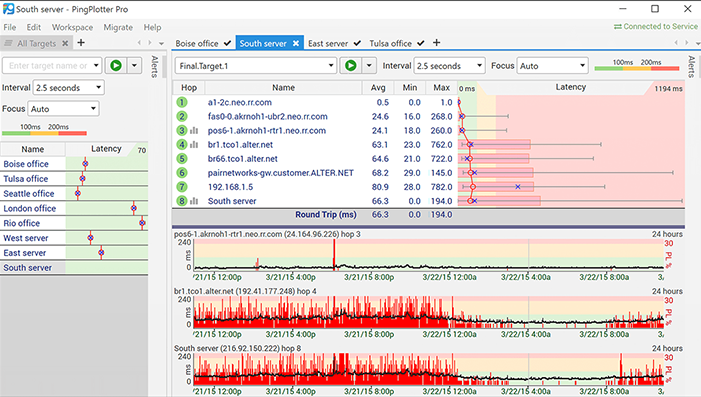
PingPlotter grafiks tīkla veiktspēju katrāPāriet starp datoru, kurā to izmantojat, un mērķa vietni, serveri vai ierīci. Rīks pārbaudīs ceļu uz jebkuru tīklam sasniedzamu ierīci. Tas parāda, kur notiek latentums, ietaupot daudz diagnostikas laika.
Lai gan ir noderīga veiktspējas statistika,viņi jums tikai saka, ka pārbaudes laikā tīkls neizdevās vai neizdevās, un kur tā ir. PingPlotter ir noderīga laika grafika funkcija, kas nodrošina dziļāku izpratni, precīzi parādot, kad rodas problēmas. Tas ļauj atšķirt konsekventu neveiksmi visa testa laikā no īsa smagas neveiksmes perioda. Tas var arī palīdzēt saistīt kļūmi ar citiem vienlaicīgiem notikumiem.
6 - multiPing
MultiPing ir vēl viens produkts ar nedaudzmaldinošs nosaukums. Lai arī tā sasniegšanai galvenokārt izmanto Ping, MultiPing patiešām ir uzraudzības sistēma, līdzīgi kā SolarWinds NPM. Protams, izmantojot Ping drīzāk SNMP nozīmē, ka jūsu iegūtā informācija ir ļoti atšķirīga. Negaidiet, ka redzēsit joslas platuma izmantošanu ar šo rīku. Tomēr viena lieta, ko redzēsit, ir latentums. Un tāpat kā joslas platuma monitori laika gaitā parādīs joslas platuma grafikus, šis arī laika gaitā iezīmēs latentumu.
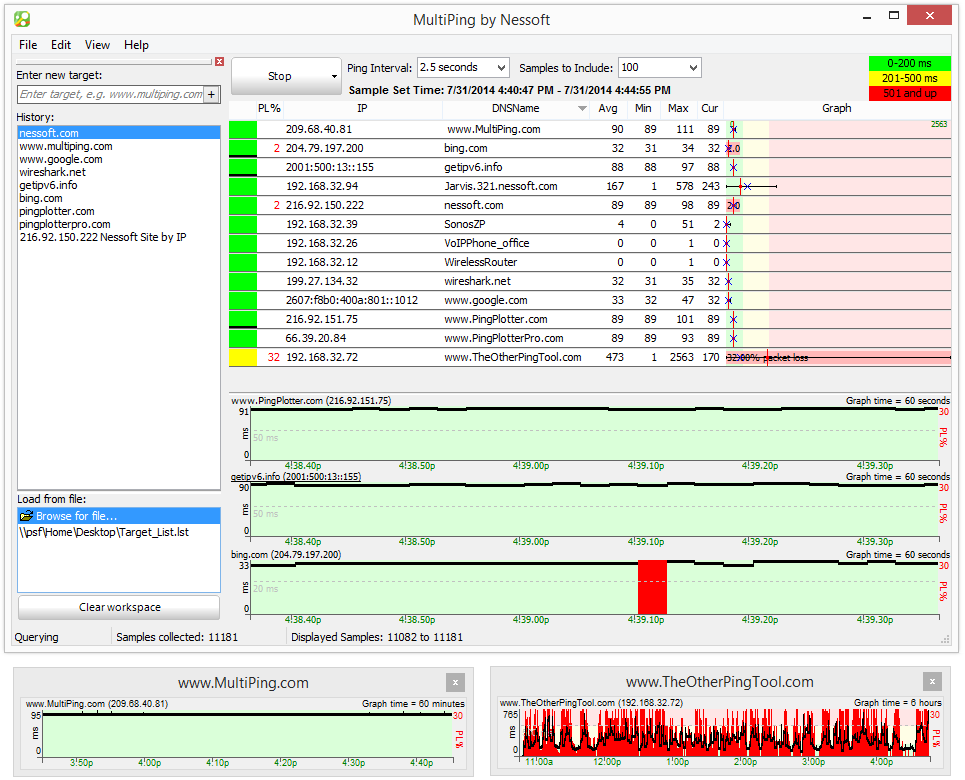
MultiPing parādīs pakešu zudumu procentoskā arī minimālo, vidējo un maksimālo latentumu. Tam ir automātiska atklāšana, padarot tā iestatīšanu par ļoti vieglu uzdevumu. Izstrādājuma lietotāja saskarni var konfigurēt pēc jūsu vēlmēm, ievietojot dažādus komponentus pēc jūsu izvēles. Sistēmai ir arī trauksme, kas var jūs informēt, kad parametri iziet no diapazona. Papildus paziņojumiem, brīdinājumos var startēt programmas.
7 - ping
Vietne jums neko nav jālejupielādē un jāinstalētomēr testa latentums. Ping ir komanda, kas iebūvēta modernākajā operētājsistēmā. Īsumā Ping nosūta virkni ICMP atbalss pieprasījumu uz mērķa IP adresi un gaida, kad tas atbildēs ar atbilstošām ICMP atbalss atbildēm. Laika posmu starp pieprasījumu un atbildi sauc par turp un atpakaļ, ko sauc arī par latentumu. Un, ja tas nesaņem atbildi uz kādu no saviem pieprasījumiem, utilīta pieņem, ka vai nu pieprasījums, vai atbilde ir pazudusi tranzītā, un apkopo informāciju par pakešu zudumiem, kas tiek parādīta, kad komanda ir pabeigusi izpildi.
8 - Traceroute (vai Tracert)
Tāpat Traceroute vai Tracert, ja jūs ieradīsitiesno Windows pasaules - var izmantot arī latentuma testēšanas nolūkiem. Šī ir vēl viena komanda, kas ir iebūvēta lielākajā daļā operētājsistēmu. Tas izmanto tāda paša veida ICMP pieprasījumus un atbildes kā Ping, bet to dara tādā veidā, kas ļauj individuāli pārbaudīt katra tīkla segmenta reakcijas laiku vai latentumu ceļa garumā. Tas ir pat labāk nekā Ping, jo tas var sniegt diezgan labu priekšstatu par to, kur notiek visvairāk latentuma. Tātad šis rīks var ne tikai izmērīt, bet arī noteikt latentumu.









Komentāri