Det virker som om nettverk aldri er raske nok. Virkelig, nettverksytelse er uten tvil det mest klagede problemet når det gjelder nettverkssystemer. Det er imidlertid en grunn til det. Nettverksytelse - eller mangel på dem - er sannsynligvis det mest synlige problemet fra en brukers synspunkt. Så når de får i oppgave å feilsøke nettverksytelsesproblemer, må nettverksadministratorer vite hva de skal se etter, hvor de skal se etter det, og de skal ha tilgang til de riktige verktøyene.
I dag har vi en grundig titt på feilsøking av ytelsesproblemer i nettverket.

Vi starter, som vi ofte gjør, med en mils høydeoversikt over hva nettverksytelsen er. Da vi kommer nærmere, vil vi se nærmere på noen av faktorene som vanligvis påvirker ytelsen til datanettverk. Vi vil først diskutere båndbredde og gjennomstrømning som til en viss grad er to sider av den samme mynten. Deretter snakker vi om forsinkelse og forsinkelse, to beregninger som ofte er forvirrede. Vi vil gjøre vårt beste for å belyse temaet.
Vår neste ordre vil være jitter, en avde mest ytelseseffektive aspektene ved nettverk. Og sist, men ikke minst, vil vi diskutere feil som noen ganger kan være konsekvensen og noen ganger symptomene på andre problemer. Og siden det å ha tilgang til de riktige verktøyene er veldig viktig når du feilsøker nettverksytelsesproblemer, vil vi se på noen av de beste nettverksovervåkingsverktøyene som kan hjelpe deg med feilsøkingsarbeidet.
Om nettverksytelse
Wikipedia definerer nettverksytelse på en veldig forenklet måte. “Nettverksytelse refererer til mål på tjenestekvaliteten i et nettverk sett av kunden”. Det er tre viktige begreper i den definisjonen. Den første har å gjøre med måleytelse. Dette er kritisk. Nettverksytelse er noe som måles. Det andre viktige konseptet er kvalitet. Ytelse refererer til kvalitet. Og sist, men absolutt ikke minst, kunden. Ytelse er noe som blir sett eller opplevd av en bruker av nettverket, ikke bare ved måleverktøy. Dette er grunnen til at det er så viktig å ha verktøy for overvåkning av nettverksytelse som kan ta målinger fra en brukers perspektiv.
Men er ikke brukerens perspektiv så høytsubjektivt konsept som kan være vanskelig å evaluere? Det er absolutt, men ved å bruke riktige verktøy og teknologier, kan det oppnås. Nøkkelen er å vite hvordan hver beregning påvirker opplevd ytelse, og dette er nettopp vårt tema for dagen.
Sagt annerledes er ytelsen til et nettverkevnen til å oppfylle brukerens forventninger. Dette er viktig siden det innebærer at ytelsen til et nettverk er brukeravhengig. Noen nettverksbrukstilfeller har veldig små ytelseskrav, mens andre trenger mer. Et godt prestasjonsnettverk er ett der den faktiske ytelsen samsvarer med bruken, og gir brukerne en oppfatning av at alt fungerer bra.
Faktorer som påvirker nettverksytelsen
Flere ting kan påvirke opplevd ytelse. Noen faktorer er ikke engang nettverksrelaterte. For eksempel kan en server som reagerer tregt tolkes som et tegn på forringelse av nettverksytelsen. Dette er enda en grunn til at vi trenger å vite hvilke nettverksfaktorer som spiller, da det gjennom en eliminasjonsprosess lar være å identifisere ytelsesproblemer som ikke er nettverk.
I de følgende avsnitt skal vi se påhvilke faktorer og parametere som samhandler for å gi brukerne oppfatningen av god - eller ikke så god - ytelse. Noen av disse faktorene er fysiske egenskaper ved nettverk som vi vanligvis ikke har kontroll over, mens andre er elementer som ofte kan forbedres, og dermed gi brukerne oppfatningen om bedre ytelse.
Båndbredde og gjennomstrømning
Båndbredde og gjennomstrømning er på en måte to siderav samme mynt. Videre er det ikke et klart skille mellom de to begrepene, og de blir ofte brukt om hverandre. Vi føler at dette er en feil da de i virkeligheten er noe forskjellige konsepter.
Båndbredde refererer vanligvis til databæringenkapasitet til et nettverk segment etter tidsenhet. Det uttrykkes vanligvis i flere bits per sekund, med megabit per sekund (Mbps) og gigabits per sekund (Gbps) som det vanligste. For eksempel har en eldre fast-Ethernet-forbindelse en båndbredde på 10 Mbps. Båndbredde er ikke noe som måles, og det er heller ikke noe som varierer over tid og med økt bruk. Det er en iboende egenskap ved et nettverk. Noen kretsløp bruker teknologier der båndbredden lett kan økes eller reduseres, men i de fleste situasjoner er det en fast parameter som ikke kan endres.
Når det gjelder gjennomstrømming, refererer det til det faktiske beløpetav data vellykket overført av tidsenhet. Trehroughput begrenses av tilgjengelig båndbredde så vel som det tilgjengelige signal-til-støy-forholdet, nettverksfeil og maskinvarebegrensninger. De fleste av de samme faktorene påvirker nettverksytelsen, påvirker gjennomstrømningen. Faktisk er gjennomstrømning en nær kusine til ytelsen. Alt er likt, jo høyere gjennomstrømning, jo høyere blir den opplevde ytelsen.
I sammenheng med opplevd nettverksytelse,båndbredde og gjennomstrømning er viktig fordi bruken av båndbredde nærmer seg den maksimale kapasiteten til et nettverkssegment, forringes ytelsen vanligvis betydelig. Dette er grunnen til at selv om båndbredden er fast, må bruken av båndbredde overvåkes.
Latency and Delay
Mye som båndbredde og gjennomstrømning, det er detofte mye forvirring mellom forsinkelse og forsinkelse. Dette er en annen situasjon der to konsepter brukes om hverandre. Begge har å gjøre med tiden det tar for data å reise fra kilden til bestemmelsesstedet. Latens blir ofte beskrevet som tiden fra kilden sender en pakke til destinasjonen som mottar den. Det kan også referere til forsinkelsestiden for tur-retur som omfattet enveis latenstid fra kilde til destinasjon pluss enveis latens fra destinasjonen tilbake til kilden. Faktisk brukes tur-retur latency oftere, hovedsakelig fordi den kan måles fra et enkelt punkt. Retur tur-retur utelukker normalt tiden et destinasjonssystem bruker på å behandle pakken og utstede svaret.
RELATERT LESING: 6 Verktøy for å administrere nettverkskonfigurasjon for alle enhetene dine
Latency er en annen fysisk egenskap vednettverk. Det er en faktor av avstanden mellom kilden og destinasjonen og lysets hastighet, som for øvrig også er hastigheten som data beveger seg over alle typer medier. Som båndbredde, er latens en fast parameter. Den eneste måten å redusere den på er å flytte kilden nærmere målet. Å redusere avstanden med rundt 100 km vil fjerne omtrent 1 millisekund forsinkelse.
Det er ganske mange andre faktorer som tilfører noenforsinkelse til nettverksoverføringene. For eksempel oppstår køforsinkelse når en gateway mottar flere pakker fra forskjellige kilder på vei mot samme destinasjon. Siden bare en pakke typisk kan overføres om gangen, må noen av dem stå i kø for overføring, medføre en ekstra forsinkelse. Også behandlingsforsinkelser oppstår mens en gateway bestemmer hva du skal gjøre med en nylig mottatt pakke. Bufferbloat kan dessuten forårsake økte forsinkelser i en størrelsesorden eller mer. Kombinasjonen av forsinkelser av forplantning, kø og prosessering resulterer ofte i en kompleks og variabel nettverksforsinkelsesprofil.
Latens og forsinkelse er de viktigste faktorene som påvirkeropplevd nettverksytelse. Heldigvis kan de lett måles enten enkelt- eller dobbeltmessig. Måling med dobbelt slutt, som beskrevet tidligere, hvis ofte foretrekkes ettersom den ignorerer destinasjonens behandlingsforsinkelse og gir en sann måling av nettverkets latenstid.
jitter
Jitter er nettets største fiende kommunikasjon og mens det er relativt enkelt å forklare, er det detnoe mer komplisert å forstå hvordan og hvorfor det kan ha en så negativ innvirkning på dataoverføringer. La oss prøve å forklare. Enkelt sagt er jitter en variant av forsinkelse. Det er flere faktorer som kan forårsake jitter. Faktisk påvirker mange av de samme faktorene som påvirker forsinkelse også jitter. For eksempel er køforsinkelser direkte relatert til kølengde. Og siden en typisk kø stadig varierer i lengde, så gjør forsinkelse, derav jitter.
Saken med jitter er at det ikke påvirkerall nettverkstrafikk på samme måte. Når forsinkelser varierer betydelig mellom flere pakker som komponerer en melding (dvs. i situasjoner med høye jitter), kan pakkene ankomme bestemmelsesstedet utenfor rekkefølgen. La oss for eksempel ta en sending som består av fire pakker som sendes med 10 ms intervaller. Den første møter 20 ms latens, den andre 60 ms, den tredje 40 ms og den siste 20 ms. Jeg sparer deg for den kjedelige regnestykket, men i en slik situasjon kommer den første pakken først, etterfulgt av den fjerde, deretter den tredje og til slutt den andre. I noen situasjoner ville dette ikke være noe problem. For eksempel, hvis vi har å gjøre med en filoverføring, er pakkene nummerert i rekkefølge og kan enkelt settes sammen i riktig rekkefølge mot mottakeren. På den annen side, hvis det vi har er trafikk i sanntid, for eksempel en direkteavspilt video eller en VoIP-samtale, har vi problemer, ettersom pakker ikke kan settes sammen på riktig måte, noe som resulterer i pikselbasert video eller forvirret lyd. Fra brukerens synspunkt har vi et resultatproblem.
feil
Til en viss grad er nettverksfeil en annenfaktor som påvirker nettverksytelsen. Bitfeil refererer til antall biter i en datastrøm mottatt over en kommunikasjonskanal som har blitt endret på grunn av støy, forstyrrelse, forvrengning eller bitsynkroniseringsproblemer. Bitfeilfrekvensen eller bitfeelforholdet (BER) er antall bitfeil dividert med det totale antall overførte biter i løpet av et gitt tidsintervall. Det uttrykkes ofte i prosent.
Selv om nettverk er veldig robuste og spenstige,de vil for det meste gjenopprette fra disse feilene ved hjelp av flere metoder, inkludert innebygde feilkorreksjonsordninger eller overføring av feil data. Men selv om disse kan være akseptable, forårsaker de ofte unødvendige forsinkelser, økte jitter og alle slags brukeropplevde ytelsesproblemer.
LES OGSÅ: Pakketap - Hvordan måle og fikse
De viktigste verktøyene for feilsøking av ytelsesproblemer i nettverket
Mens det er mange verktøy for å målenettverksytelse, ikke alle av dem er like funksjonelle som de få vi har valgt for deg. De beste viser ikke bare båndbredde, men også flere båndbreddepåvirkende beregninger, for eksempel latens eller jitter, og hjelper deg dermed raskt å feilsøke nettverksytelsen som er utstedt.
1. SolarWinds Network Performance Monitor (GRATIS PRØVEPERIODE)
Solarwinds er en av de mest kjente leverandørene av nettverks- og systemadministrasjonsverktøy. Det er kjent for sine mange utmerkede verktøy for nettverksadministrasjon. Blant de mest kjente Solarwinds produktene er NetFlow Traffic Analyzer og Server og applikasjonsmonitor. Selskapet er også anerkjent for å lage en håndfull utmerkede gratis verktøy, som hver for seg adresserer et spesifikt behov for nettverks- og systemadministrator. De Avansert subnettkalkulator og Kiwi Syslog Server er to gode eksempler på de gratis verktøyene.
SolarwindsFlaggskipproduktet kalles Network Performance Monitor, eller NPM. Dette er en fullverdig nettverksovervåkingsløsning med god funksjonalitet. De SolarWinds NPM avstemmer alle aktiverte enheter ved hjelp av SNMP-protokollenå lese deres operasjonelle beregninger og grensesnitt tellere. Den lagrer resultatene i en SQL-database og bruker undersøkte data for å lage grafer som viser hver WAN-krets bruk samt andre viktige beregninger.
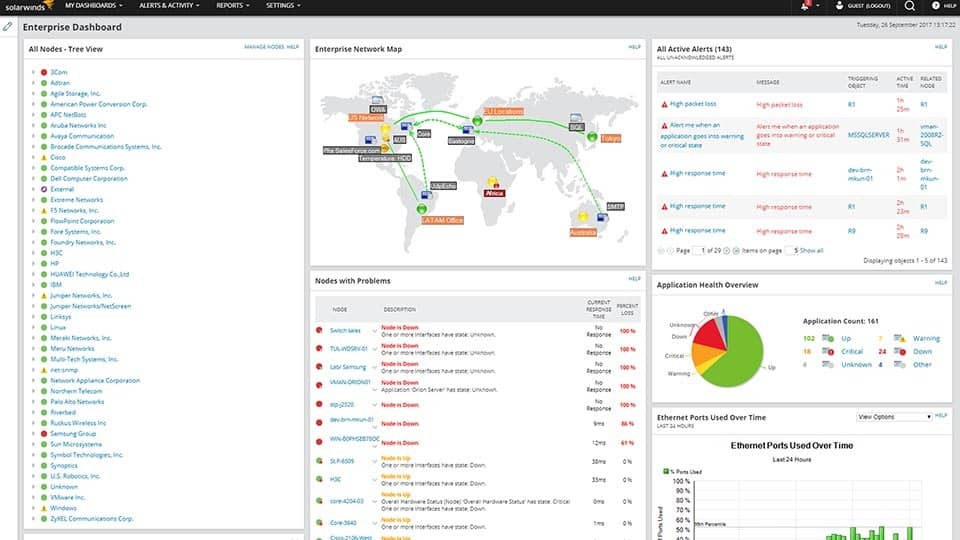
- GRATIS PRØVEPERIODE: SolarWinds Network Performance Monitor
- Last ned lenke: https://www.solarwinds.com/network-performance-monitor/registration
SolarWinds Network Performance Monitor kan skryteet brukervennlig GUI. Med det er å legge til en enhet så enkelt som å spesifisere IP-adressen eller vertsnavnet og SNMP-fellesskapsstrengen. Verktøyet spør deretter om enheten, lister opp alle SNMP-parametrene som er tilgjengelige, og lar deg velge de du vil overvåke og vise på grafene dine.
Prisene for SolarWinds Network Performance Monitor starter på 2 995 dollar og varierer i henhold til antall enheter som skal overvåkes. Du kan få et detaljert tilbud ved å kontakte SolarWinds salgsteam.
Hvis du vil prøve produktet før du kjøper det, er det en gratis 30-dagers prøveversjon tilgjengelig, som for de fleste SolarWinds-produkter.
2. ManageEngine OpManager
De ManageEngine OpManager er en komplett styringsløsning som vilimøtekomme de fleste overvåkingsbehov. Verktøyet kan kjøres på enten Windows eller Linux, og det er lastet med utmerkede funksjoner. For eksempel kan dens auto-discovery-funksjon grafisk kartlegge nettverket ditt, noe som gir deg et unikt tilpasset dashbord.
Verktøyets instrumentbord er et annet av dets sterkepunkter. Det er superenkelt å bruke og navigere og har drill-down funksjonalitet. Hvis du bruker mobilapper, er de tilgjengelige for nettbrett og smarttelefoner og lar deg få tilgang til systemet hvor som helst. Totalt sett er dette et veldig polert og profesjonelt produkt.
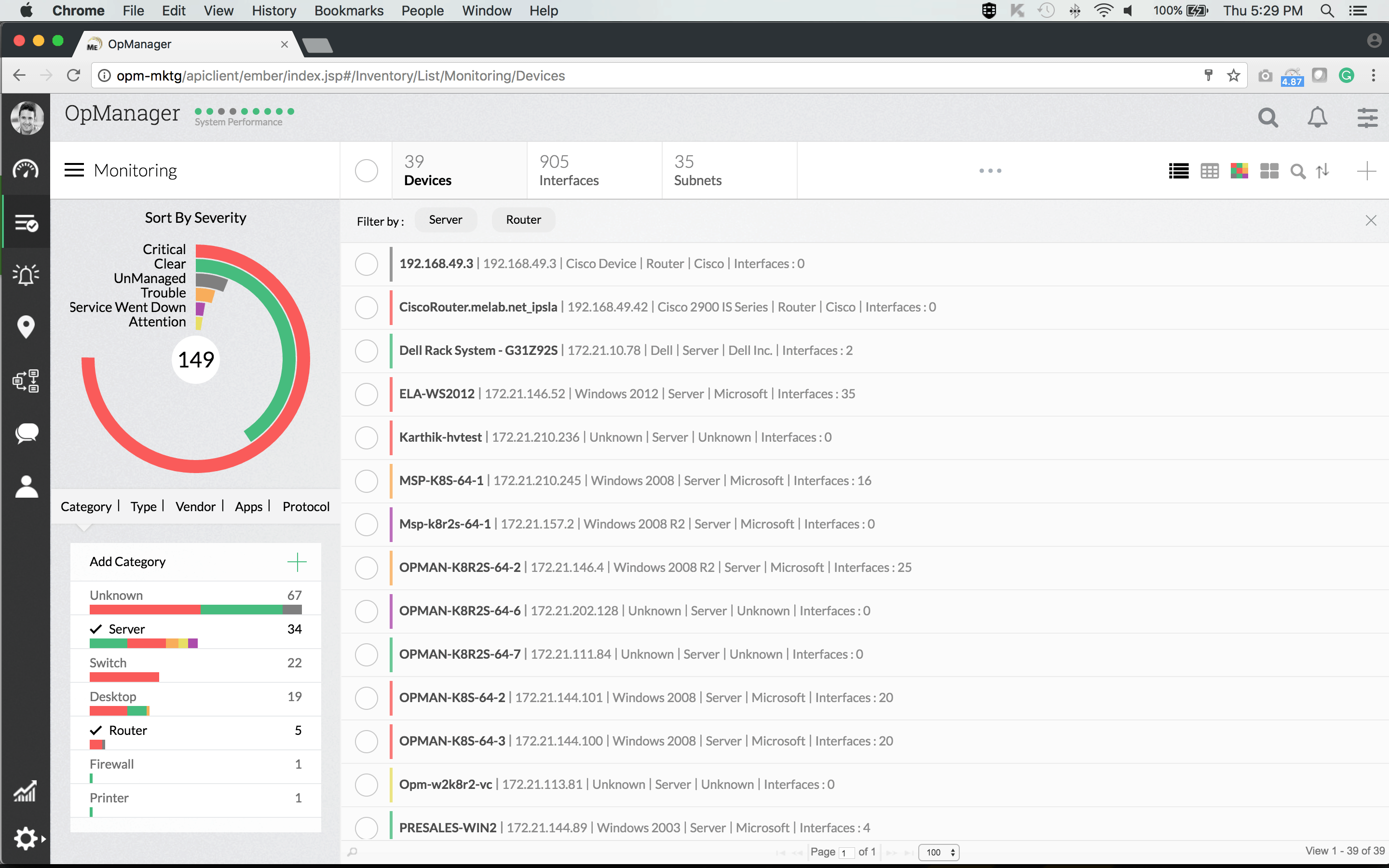
Varsler inn OpManager er en annen av produktets styrker. Det er et komplett komplement av terskelbaserte varsler som vil bidra til å oppdage, identifisere og feilsøke nettverksproblemer. Flere terskler med forskjellige varsler kan settes for hver resultatmåling.
Hvis du vil prøve ManageEngine OpManager, få gratisversjonen. Det er ikke en tidsbegrenset prøveversjon. Det er i stedet funksjonsbegrenset. Det lar deg for eksempel ikke overvåke mer enn ti enheter. Selv om dette kan være tilstrekkelig for testformål, vil det bare passe til de minste nettverkene. For flere enheter kan du velge mellom Viktig eller Bedriften planer. Den første lar deg overvåke opptil 1 000 noder, mens den andre går opp til 10 000. Prisinformasjon er tilgjengelig ved å kontakte ManageEngineSalg.
3. PRTG Network Monitor
De PRTG Network Monitor fra Paessler AG er et agentfritt nettverksovervåkingssystem. Paessler hevder at PRTG Network Monitor kan settes opp i løpet av et par minutter. Vår erfaring viser at det kan ta litt mer enn det, men at det fortsatt er veldig enkelt og raskt, takket være en auto-funnfunksjon som vil skanne nettverket ditt, finne enheter og automatisk legge dem til. Verktøyet bruker en kombinasjon av Ping, SNMP, WMI, NetFlow, jFlow, sFlow, men kan også kommunisere via DICOM eller RESTful API.
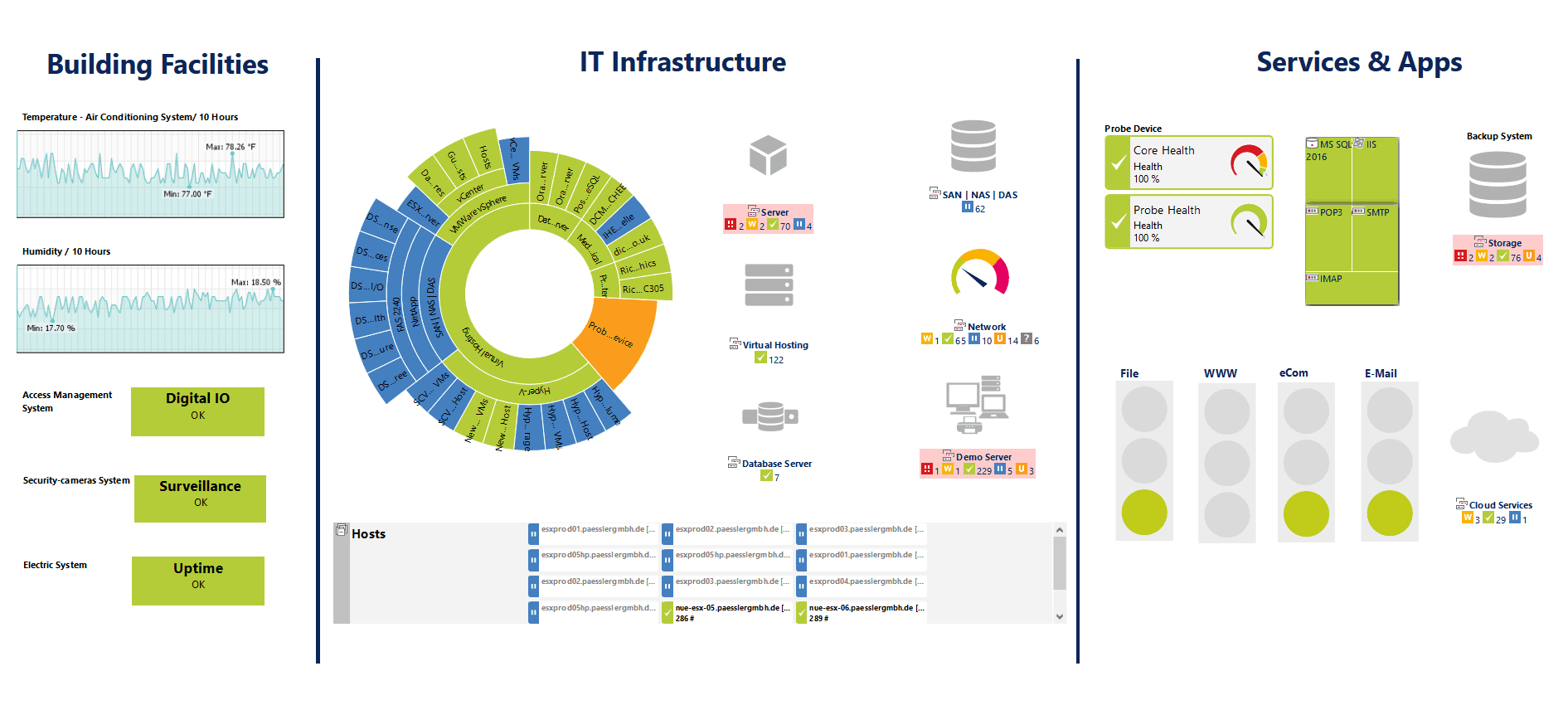
En av styrkene til PRTG Network Monitor er dens sensorbaserte arkitektur. Du kan tenke på sensorer som tillegg til produktet bortsett fra at de allerede er inkludert og ikke trenger å bli lagt til. Det finnes tillegg for praktisk talt hva som helst. For eksempel er det HTTP, SMTP / POP3 (e-post) applikasjonssensorer. Det finnes også maskinvarespesifikke sensorer for brytere, rutere og servere. I alt er det over 200 forskjellige forhåndsdefinerte sensorer som henter statistikk som responstid, prosessor, minne, databaseinformasjon, temperatur eller systemstatus fra de overvåkede enhetene.
De PRTG Network Monitor tilbyr et utvalg av brukergrensesnitt. Den primære er et Ajax-basert nettgrensesnitt. Det er også en Windows-konsoll i tillegg til mobilapper for Android og iOS. En fin funksjon ved mobilappene er at de kan bruke pushvarsling om eventuelle varsler utløst fra PRTG. Mer standard SMS- eller e-postvarsler er også tilgjengelig. Selv om serveren bare kjører på Windows, kan den administreres fra alle enheter med en Ajax-kompatibel nettleser.
De PRTG Network Monitor tilbys i to versjoner. Det er en gratis versjon som er fullverdig, men som vil begrense overvåkningsevnen din til 100 sensorer. Merk at hver overvåket parameter teller som en sensor, og for eksempel monitor 24-grensesnitt på en nettverksbryter vil bruke opp 24 sensorer. Hvis du trenger mer enn 100 sensorer, må du kjøpe en lisens. Prisene deres starter på $ 1 600 for 500 sensorer. Du kan også få en gratis, sensor-ubegrenset og fullverdig 30-dagers prøveversjon.









kommentarer