Latenția rețelei este adesea inamicul numărul unu aladministratorii de rețea. Se pare că se târâie peste tot și te lovește mereu atunci când ai nevoie cel puțin. Apoi, din nou, probabil că nu ai nevoie niciodată. Latenția poate fi de natură să facă rețeaua dvs. abia utilizabilă. Deci, ce se poate face în acest sens? Primul pas este să descoperiți latențe. Apoi, trebuie să îl măsurați și să îl localizați. Abia atunci veți putea face ceva pentru rezolvarea acestuia. Pentru a vă ajuta, am compilat o listă de instrumente de testare a latenței de rețea care vă pot ajuta la descoperirea și măsurarea problemelor de latență.

Înainte de a începe, vom încerca să explicăm ce anumelatența este și ceea ce o provoacă. Acest lucru vă va ajuta să înțelegeți mai bine cum pot ajuta diferitele instrumente. De asemenea, vom examina importanța latenței și modul în care aceasta afectează utilizarea rețelei. Apoi, vom analiza cum putem măsura latența rețelei. Și având în vedere că este inutil să găsim și să măsurăm latența dacă nu se face nimic în acest sens, vom discuta și despre reducerea latenței rețelei. Vom fi apoi gata să vă prezentăm lista cu cele mai bune instrumente de testare a latenței în rețea. Dar veți vedea că nu este doar o listă, vom examina, de asemenea, pe scurt fiecare dintre instrumente.
Ce este latența rețelei?
Într-o propoziție, latența rețelei este o măsură atimpul necesar pentru ca un pachet de date să ajungă de la sursă la destinație. Intr-o lume ideala, ar exista latenta zero. Dar, în realitate, vor exista întotdeauna unele. Deși latența este inevitabilă, trebuie întotdeauna să se asigure că nu devine atât de importantă încât începe să afecteze funcționarea normală a unei rețele.
Câțiva factori contribuie la latență. În primul rând, există timpul de propagare. Deși rețelele sunt rapide, iar biții se deplasează cu viteza luminii, mai este nevoie de ceva timp pentru a ajunge la destinație. Și cu cât calea este mai lungă, cu atât va dura mai mult timp. Din acest motiv, latența dintre două computere situate la mii de kilometri unul de altul va fi, în mod normal, mai mare decât între calculatoarele din aceeași cameră.
Un alt factor contribuitor se numeșteîntârziere de transmitere. Aceasta este o întârziere care poate fi introdusă de mediul însuși. De asemenea, provine de la dimensiunea pachetelor de date. Pachetele mai mari vor avea o latență mai mare, deoarece necesită mai mult timp pentru livrare.
Router și alte întârzieri de procesare sunt, de asemenea, osursa de latență a rețelei. Chiar și pe circuite abia utilizate, în care coada este absentă, fiecare router trebuie să manipuleze datele. De exemplu, câmpul antet TTL trebuie decrementat.
De fapt, multe alte întârzieri pot afecta dateletransmisie. Ne putem gândi la întârzieri în coadă care se întâmplă atunci când datele nu pot fi trimise imediat sau întârzieri de stocare atunci când trebuie să fie memorate în cache pe disc sau în memorie și apoi să fie recuperate.
Măsurarea latenței
Măsurarea latenței poate fi mai complicată decât eaarată. Acest lucru este valabil în special atunci când se măsoară latența între puncte foarte îndepărtate. Există câteva motive pentru asta, dar se datorează în mare parte faptului că chiar și latența uriașă este încă relativ scurtă, de ordinul a câteva miimi de secundă. Nu poți să-ți suni cu adevărat prietenul la celălalt capăt și să-i spui „OK, îți trimit un pachet, spune-mi când va ajunge” și măsoară întârzierea. Șansele sunt ca pachetul să ajungă înainte de a vorbi chiar. Uită de calendarul ei.
De obicei, latența este măsurată prin trimiterea unuipachet care este returnat expeditorului și măsurând timpul necesar pentru ca răspunsul să revină. Este ca acest timp dus-întors este considerat a fi latența. Există câteva dezavantaje ale acestei metode de evaluare. De exemplu, dacă calea de întoarcere este diferită, cifra de latență nu vă va spune care dintre căile de înaintare sau retur se confruntă cu latență.
O altă problemă posibilă este aceea că tipurile depachetele utilizate pentru măsurarea latenței - de obicei cererile și răspunsurile ICMP - nu sunt întotdeauna tratate de dispozitivele de rețea cu aceeași prioritate ca și un alt trafic de rețea.
De ce este importantă latența?
Răspunsul ușor aici este evident: deoarece atunci când latența devine prea mare, aceasta poate afecta capacitatea de utilizare a rețelelor. Așadar, nu este latența în sine importantă, ci urmărirea. Latența neobișnuit de mare sau mai mare decât de obicei - este adesea un semn că ceva nu este în regulă în rețea sau în rețea. De cele mai multe ori, va fi consecința congestiei. Rețelele sunt ca autostrăzile și atunci când există prea mult trafic, lucrurile încetinesc și obțineți o latență mare.
Dar latența măsurată nu este întotdeauna o indicațiea unei probleme de rețea. Deoarece măsurăm de obicei latența prin măsurarea timpului dus-întors, o altă sursă de latență ar putea fi dispozitivul îndepărtat. Dacă dispozitivul este foarte ocupat făcând orice este, trebuie să nu răspundă imediat la solicitarea ICMP pe care a primit-o de la gazda de testare. Când se va întâmpla acest lucru, va fi perceput ca latență de rețea, dar, de fapt, nu are nicio legătură cu rețeaua și măsurarea latenței dvs. nu vă va oferi un indiciu în acest sens.
În mod similar, utilizatorii ar putea experimenta latențănu are nicio legătură cu rețeaua. Latența aplicației este posibil la fel de comună ca latența de rețea. Când serverele sunt supraîncărcate, începe să răspundă mai lent. La fel ca rețelele când sunt congestionate. Dar latența pentru server și aplicație nu este subiectul de azi.
Reducerea latenței rețelei
Este un lucru (enervant) să experimentezi latențași este un alt lucru pentru a-l măsura, dar ce bine este dacă nu găsiți o modalitate de a-l reduce. Există mai multe modalități prin care poți face acest lucru. Pe scurt, modul de rezolvare a latenței ridicate depinde de ceea ce o provoacă. Și având în vedere că cea mai frecventă cauză de latență este utilizarea excesivă a rețelei, să vedem ce se poate face în acest sens.
Circuitele de rețea nu sunt nelimitate și când suntobțineți o utilizare excesivă, apare congestia și utilizatorii au o latență ridicată. Funcționează exact ca traficul de autostradă. Acest lucru este valabil în special pentru circuitele WAN, care au adesea o lățime de bandă limitată.
Deci, pentru a reduce latența, cel mai bun mod este - ai face-ol-am ghicit - pentru a reduce utilizarea rețelei. Dar, desigur, acest lucru nu este întotdeauna posibil. Aici intervine optimizarea rețelei. Am putea scrie un articol întreg despre optimizarea WAN. De fapt, recent am făcut-o. Și există multe instrumente pe care le puteți utiliza pentru a ajuta la această sarcină.
Cele mai bune instrumente pentru măsurarea latenței
După cum știm acum, pentru a remedia problemele de latență, mai întâitrebuie să-l măsurăm și să localizăm de unde provine. Aici vă pot ajuta instrumentele pe care urmează să le dezvăluim. Unii vor măsura pur și simplu latența, în timp ce alții te vor ajuta. Alții totuși măsoară utilizarea lățimii de bandă care poate ajuta deoarece știm că excesul de utilizare este cauza principală a latenței ridicate. Instrumentele sunt grupate după tip, mai degrabă decât după preferințe.
1 - Monitorul de performanță al rețelei SolarWinds (Încercare gratuită)
SolarWinds este unul dintre cei mai cunoscuți producătoriinstrumente de administrare a rețelei Compania este în vârstă de vârstă și este, de asemenea, renumită pentru multiplele instrumente gratuite, fiecare adresând o nevoie specifică administratorilor de rețea. Mai multe dintre instrumentele gratuite au fost revizuite în aceste pagini, în timp ce am discutat despre cele mai bune servere TFTP ale celor mai bune servere syslog.
Monitorul de performanță al rețelei SolarWinds sauNPM, este produsul principal al SolarWind. Probabil unul dintre cele mai bune instrumente de monitorizare a lățimii de bandă SNMP, este încărcat cu atât de multe caracteristici încât am putea vorbi despre asta ore întregi. Cel mai bun avantaj al instrumentului este cel mai probabil simplitatea sa. Dar această simplitate nu vine la prețul flexibilității. Tablouri de bord, vizualizări, diagrame și rapoarte pot fi complet personalizate în funcție de preferințele sau nevoile dvs. Instrumentul poate fi configurat în câteva minute și se poate extinde de la cea mai mică rețea la cele uriașe cu mii de dispozitive.
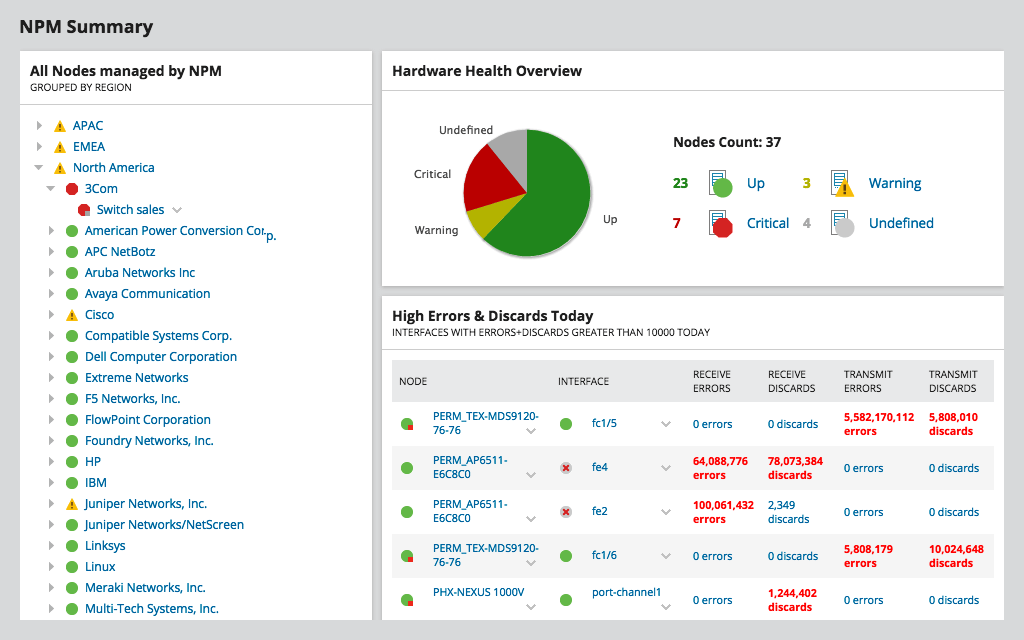
NPM nu va măsura direct latența rețelei,deşi. Dar, oferindu-vă informații detaliate despre utilizarea lățimii de bandă a fiecărei părți a rețelei dvs., vă va permite să identificați rapid punctele cu probleme în care congestionarea ar putea fi cauza unei latențe ridicate.
NPM folosește SNMP pentru a interzice periodic dispozitivele taleși citiți contoarele de interfață, calculând utilizarea lățimii de bandă și afișând-o sub formă de grafice. Configurarea instrumentului necesită doar să specificați adresa IP și șirul comunității unui dispozitiv. Funcțiile avansate vă permit să construiți hărți de rețea și să afișați calea critică între două dispozitive, o caracteristică excelentă la depanarea latenței.
Prețul pentru monitorizarea performanței rețelei începe de la 2 955 USD. Dacă doriți să încercați instrumentul înainte de a-l achiziționa, este disponibil un proces complet de 30 de zile.
2 - SolarWinds NetFlow Traffic Analyzer (Încercare gratuită)
Un alt produs excelent de la SolarWinds,NetFlow Traffic Analyzer poate oferi administratorilor o vedere mai detaliată a traficului de rețea. Nu numai că vă va arăta utilizarea și latența potențială, dar vă va arăta și unde se întâmplă și de multe ori ceea ce o provoacă. Instrumentul oferă informații detaliate despre traficul observat. De exemplu, instrumentul vă va permite să aflați ce tip de trafic sau ce utilizator consumă cea mai mare lățime de bandă. Tabloul de bord al NetFlow Traffic Analyzer are mai multe vizualizări utile, cum ar fi aplicații de top, protocoale de top sau vorbitori de top.
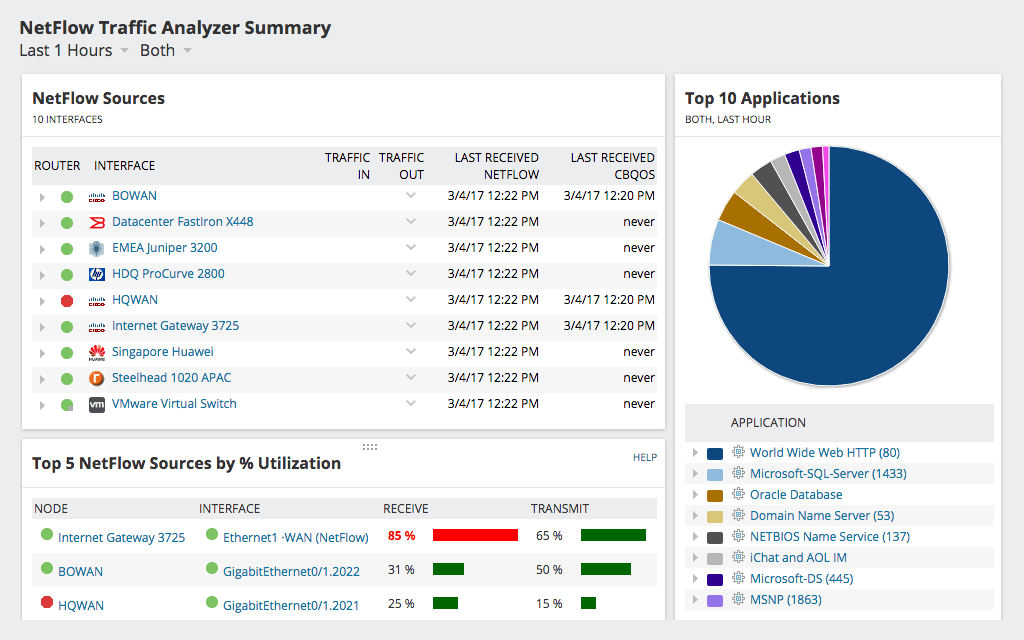
SolarWinds NetFlow Traffic Analyzer foloseșteProtocolul NetFlow pentru a aduna informații detaliate despre utilizare de pe dispozitivele de rețea. Creat inițial de Cisco, protocolul NetFlow permite dispozitivelor să trimită informații detaliate despre fiecare „conversație” sau flux, către un colector și analizor NetFlow, cum ar fi NetFlow Traffic Analyzer. Aceste informații conțin mai multe elemente care pot fi utilizate pentru a analiza traficul. Mulți producători, în afară de Cisco, includ, de asemenea, funcționalitatea NetFlow sau un echivalent în echipamentele lor, numind uneori un nume diferit. Recent, protocolul NetFlow a fost standardizat ca IPFIX, sau IP Flow Information Exchange, de către IETF. SolarWinds NetFlow Traffic Analyzer va funcționa cu toate variantele protocolului, ceea ce îl face o alegere excelentă.
Analizatorul de trafic SolarWinds NetFlow este unmodul suplimentar care se instalează în partea de sus a monitorizării performanței rețelei. Prețul începe de la 1 915 USD și variază în funcție de numărul de gazde. La fel ca în cazul majorității produselor plătite de SolarWind, este disponibil un proces gratuit.
3 - Paessler PRTG
Graficul de trafic Paessler Router, sau PRTG, esteun alt instrument de monitorizare a lățimii de bandă. Și este una dintre cele mai ușoare și rapide de instalat. Paessler susține că ați putea fi în funcțiune în câteva minute și, într-adevăr, configurarea produsului nu durează mult timp, chiar dacă este mai mult decât se pretinde. Produsul are o caracteristică de descoperire automată, ceea ce înseamnă că vă va scana rețeaua și va adăuga automat componentele pe care le găsește.
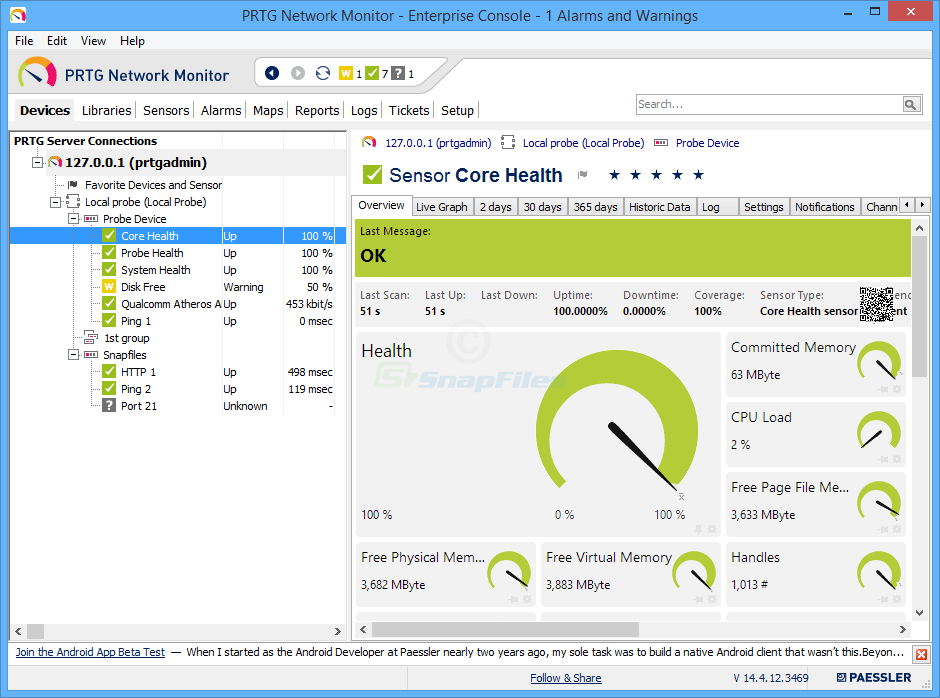
PRTG vine standard cu mai multe interfețe de utilizator,permițându-ți să-l alegi pe cel care se potrivește cel mai bine nevoilor tale. Există o aplicație nativă pentru consola Windows, există și o interfață web bazată pe Ajax și există aplicații mobile pentru Android și iOS. Și folosește foarte mult capacitățile fiecărei platforme. De exemplu, aplicațiile mobile vă vor permite să accesați detaliile oricărui dispozitiv, pur și simplu scanând o etichetă de cod QR atașată la acesta. Desigur, consola Windows vă va permite să imprimați acele etichete.
PRTG folosește o combinație de tehnologiimonitorizarea. Va folosi monitorizarea SNMP, dar și WMI pentru dispozitivele Windows și NetFlow și Sflow, două tehnologii de analiză a fluxurilor similare, dar concurente. Și instrumentul are mai mulți senzori special concepuți pentru a măsura latența. Există un senzor QoS care va măsura întârzierea dus-întors, un senzor Cisco IP SLA și un senzor Ping.
4 - ManageEngine NetFlow AnalYzer
Analizatorul ManageEngine NetFlow este altulInstrument de monitorizare bazat pe NetFlow care prezintă unele funcții avansate de monitorizare a latenței. Instrumentul oferă o vedere detaliată a utilizării rețelei și a modelelor de trafic. Interfața sa de utilizator pe internet vă va permite să vizualizați traficul prin aplicație, conversație, protocol și multe altele. Tabloul de bord complet al instrumentului este una dintre cele mai bune caracteristici ale sale. Oferă unele dintre cele mai bune versatilități și vă va permite să includeți orice date doriți. Și pentru administratorii din mers, există aplicații mobile disponibile.
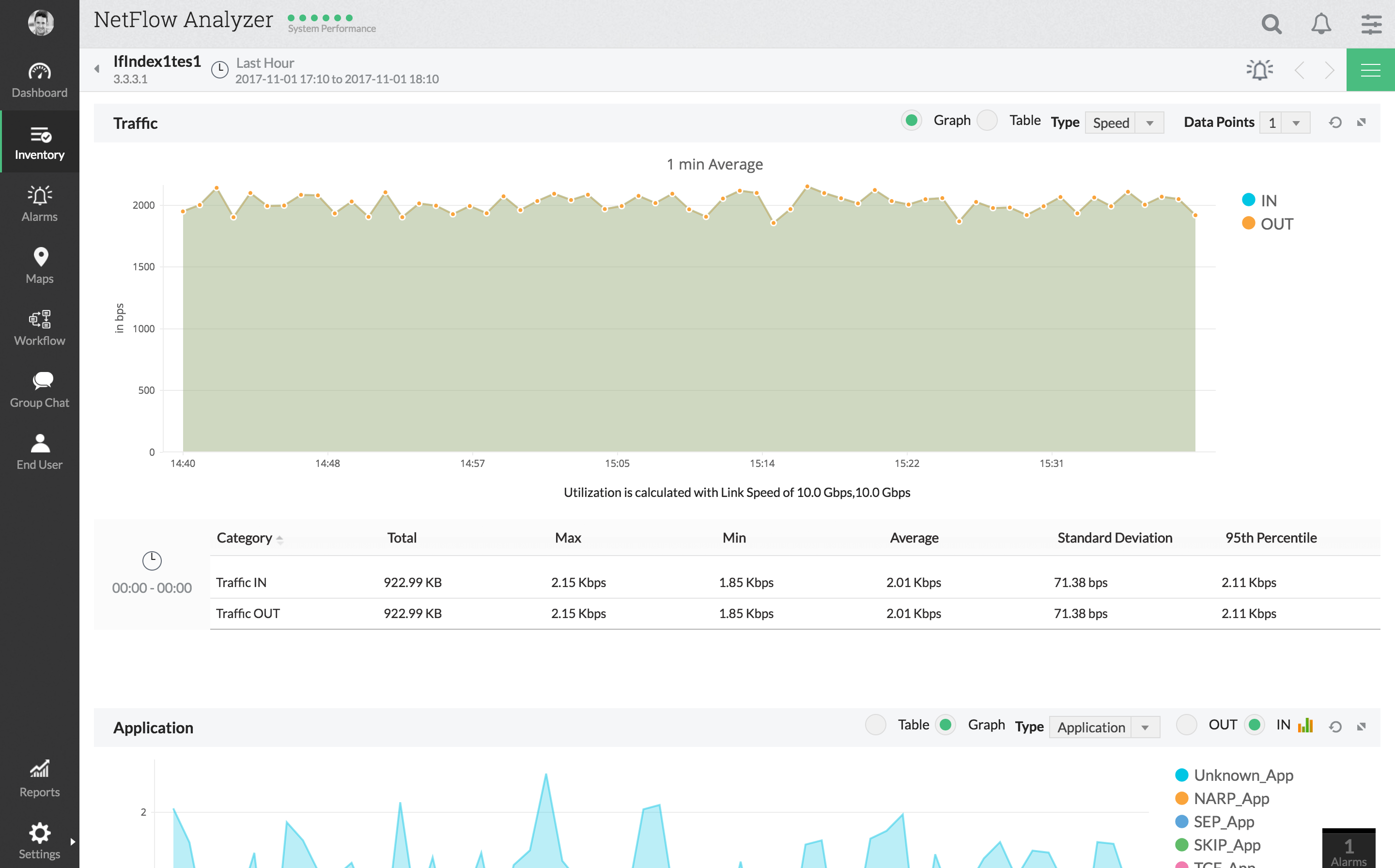
Suportul ManageEngine NetFlow Analyzer este compatibilmai multe tehnologii de flux, inclusiv NetFlow, IPFIX, J-flow, NetStream și câteva altele. Ca bonus, prea are o integrare excelentă cu dispozitivele Cisco, cu suport pentru ajustarea modelării traficului și / sau a politicilor QoS chiar de pe instrument.
Și pentru măsurarea latenței, acest instrument dispune de un monitor WT Time Trip Trip (RTT) care vă permite să monitorizați disponibilitatea WAN, latența și calitatea serviciilor.
5 - PingPlotter
În ciuda numelui său înșelător, PingPlotter estede fapt un software grafic Traceroute care poate ajuta la rezolvarea problemelor de rețea. Acest instrument de diagnostic grafică latența și pierderea de pachete între computer și țintă. Vă permite să vizualizați informațiile, să accelereze procesul de soluționare a problemelor și vă pot ajuta să construiți un caz dacă trebuie să convingeți pe cineva că există o problemă la sfârșitul lor.
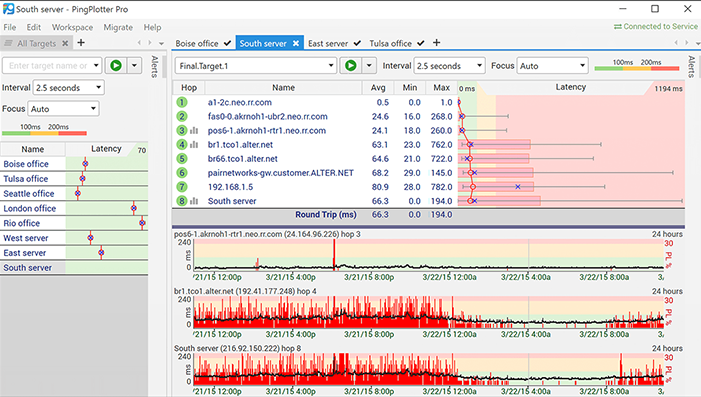
PingPlotter grafică performanța rețelei la fiecaresalt între computerul pe care îl rulați și un site web, server sau dispozitiv țintă. Instrumentul va testa calea către orice dispozitiv accesibil în rețea. Afișează unde se întâmplă latența, economisindu-vă mult timp de diagnostic.
În timp ce deține statistici de performanță este util,ei vă spun doar că rețeaua a eșuat - sau nu a reușit - în timpul testului și unde se află eșecul. PingPlotter are o caracteristică de timp utilă care oferă un nivel mai profund de înțelegere, arătând exact când apar probleme. Acest lucru vă permite să diferențiați între un eșec constant pe parcursul testului și o perioadă scurtă de eșec sever. De asemenea, poate ajuta la corelarea eșecului cu alte evenimente simultane.
6 - MultiPing
MultiPing este un alt produs cu oarecumnume înșelător. Deși folosește în principal Ping pentru a-și îndeplini funcția, MultiPing este într-adevăr un sistem de monitorizare, cum ar fi NPM-ul SolarWinds. Desigur, utilizarea Ping mai degrabă a SNMP înseamnă că informațiile pe care le veți obține sunt foarte diferite. Nu vă așteptați să vedeți utilizarea lățimii de bandă cu acest instrument. Un lucru pe care îl veți vedea este însă latența. Și la fel cum monitoarele de lățime de bandă vor reprezenta graficele de lățime de bandă de-a lungul timpului, acesta va complota latența în timp.
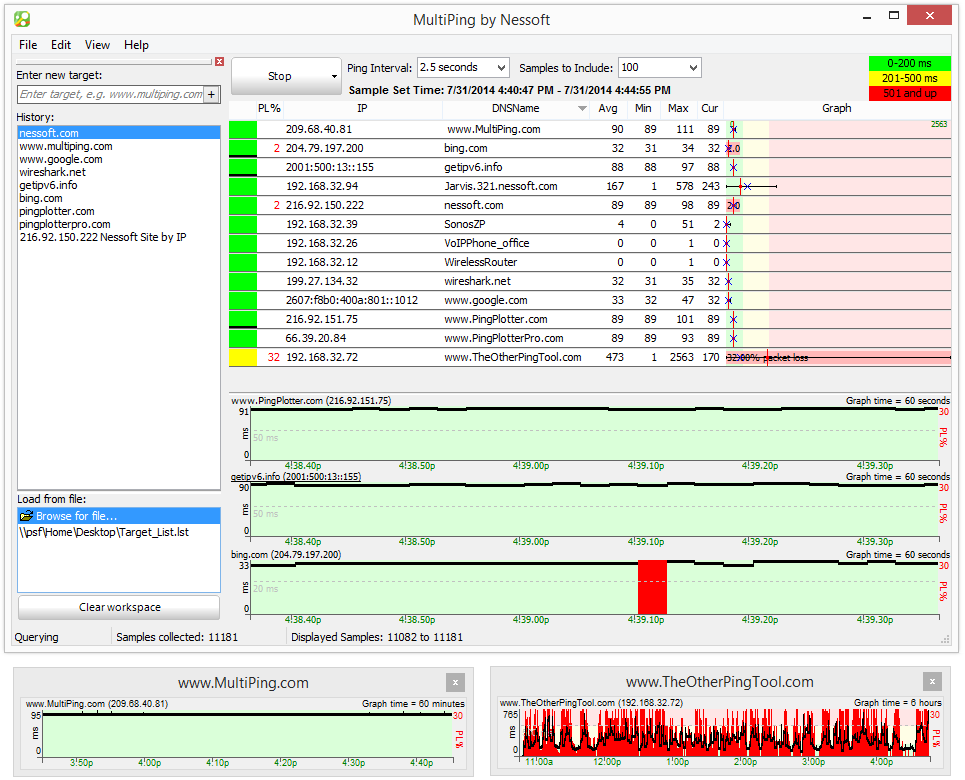
MultiPing vă va prezenta pierderea de pachete în procenteprecum și latența minimă, medie și maximă. Are auto-descoperire, făcând configurarea sa o sarcină super ușoară. Interfața de utilizator a produsului poate fi configurată după bunul plac, punând diferite componente pe măsură ce considerați de cuviință. De asemenea, sistemul oferă alerte care vă pot notifica atunci când parametrii ies din raza de acțiune. Pe lângă notificări, programele pot fi lansate pe alerte.
7 - Ping
Nu trebuie să descărcați sau să instalați nimiclatența testului, totuși. Ping este o comandă care este construită chiar în majoritatea sistemelor de operare moderne. Pe scurt, Ping trimite o serie de solicitări de ecou ICMP la adresa IP țintă și așteaptă să răspundă cu răspunsurile ecografice ICMP corespunzătoare. Întârzierea dintre cerere și răspuns este denumită întârziere dus-întors, care este de asemenea denumită latență. Și atunci când nu reușește să primească un răspuns la una dintre solicitările sale, utilitatea presupune că fie cererea, fie răspunsul s-a pierdut în tranzit și compila informațiile despre pierderea pachetelor care sunt afișate odată ce comanda termină executarea.
8 - Traceroute (Sau Tracert)
În mod similar, Traceroute - sau Tracert dacă vinețidin lumea Windows - poate fi folosit și în scopuri de testare a latenței. Aceasta este o altă comandă care este încorporată în majoritatea sistemelor de operare. Utilizează același tip de cereri și răspunsuri ICMP ca Ping, dar o face într-un mod care îi permite să testeze individual timpul de răspuns sau latența fiecărui segment de rețea de-a lungul căii. Acest lucru este chiar mai bun decât Ping, deoarece vă poate oferi o idee destul de bună despre locul în care se întâmplă cea mai mare parte a latenței. Așadar, acest instrument nu numai că poate măsura, dar și localiza latența.









Comentarii