Network Latency är ofta den främsta fienden tillnätverksadministratörer. Det verkar vara att krypa upp överallt och alltid slå dig när du minst behöver det. Återigen behöver du förmodligen aldrig det. Latency kan vara sådan att ditt nätverk knappt kan användas. Så vad kan man göra åt det? Steg ett är att upptäcka latenser. Sedan måste du mäta den och hitta den. Först då kan du göra något åt att lösa det. För att hjälpa dig har vi sammanställt en lista över verktyg för testning av nätverks latens som kan hjälpa dig att upptäcka och mäta latensproblem.

Innan vi börjar försöker vi förklara vadlatens är och vad som orsakar det. Detta hjälper dig att bättre förstå hur de olika verktygen kan hjälpa dig. Vi kommer också att undersöka vikten av latens och hur det påverkar nätverksanvändningen. Sedan tittar vi på hur vi kan mäta nätverkslatens. Och eftersom det är värdelöst att hitta och mäta latens om ingenting görs åt det kommer vi också att diskutera minskning av nätverks latens. Vi är då redo att presentera vår lista över de bästa verktygen för testning av nätverksfördröjning. Men du kommer att se att det inte bara är en lista, vi granskar också korta verktyg.
Vad är nätverkslatency?
I en mening är nätverks latens ett mått påden tid det tar för ett datapaket att komma från sin källa till sin destination. I en idealvärld skulle det finnas noll latens. Men i verkligheten kommer det alltid att finnas några. Och även om latens är oundviklig, måste man alltid se till att det inte blir så viktigt att det börjar påverka den normala driften av ett nätverk.
Flera faktorer bidrar till latens. För det första finns det förökningstid. Även om nätverk är snabba och bitarna går med ljusets hastighet tar det fortfarande lite tid att nå målet. Och ju längre väg, desto mer tid tar det. Av den anledningen är fördröjningen mellan två datorer som ligger tusentals mil från varandra normalt sett högre än mellan datorer i samma rum.
En annan bidragande faktor kallasöverföringsfördröjning. Detta är en försening som kan införas av mediet själv. Det kommer också från datapaketen. Större paket har högre latens eftersom de tar mer tid att leverera.
Router och andra behandlingsförseningar är också enkälla till nätverks latens. Även på knappt använda kretsar där kö är frånvarande måste varje router manipulera data. Till exempel måste TTL-rubrikfältet minskas.
Faktum är att många fler förseningar kan påverka dataöverföring. Vi kan tänka på förseningar i kö som inträffar när data inte kan skickas omedelbart eller lagringsfördröjning när det måste cache till skiva eller minne och sedan hämtas.
Mät latens
Att mäta latens kan vara mer komplicerat än detutseende. Detta är särskilt sant när man mäter latens mellan mycket avlägsna punkter. Det finns några orsaker till det, men det beror främst på att till och med enorm latens är fortfarande relativt kort, i storleksordningen några tusendels sekund. Du kan inte riktigt ringa din vän i andra änden och säga honom "OK, jag skickar ett paket, berätta när det kommer" och mät förseningen. Chansen är stor att paketet kommer att anlända innan du ens har pratat. Glöm timing det.
Typiskt mäts latens genom att skicka enpaket som returneras till avsändaren och mäter tiden det tar för svaret att komma tillbaka. Det är den här rundturstiden anses vara latensen. Det finns några nackdelar med denna utvärderingsmetod. Om returbanan till exempel är annorlunda berättar inte latensfiguren vilken av framåt- eller returvägar som upplever latens.
En annan möjlig fråga är att typerna avpaket som används för att mäta latens - vanligtvis ICMP-förfrågningar och svar - behandlas inte alltid av nätverksenheterna med samma prioritet som någon annan nätverkstrafik.
Varför är latens viktigt?
Det enkla svaret här är uppenbart: eftersom när latensen blir för hög kan det påverka användbarheten i nätverk. Så det är inte latens i sig som är viktigt men att se på det. Ovanligt högt - eller högre än vanligt - latens är ofta ett tecken på att något är fel med nätverket eller i nätverket. För det mesta kommer det att vara en följd av trängsel. Nätverk är som motorvägar och när det är för mycket trafik, saknar saker och du får hög latens.
Men uppmätt latens är inte alltid en indikationav ett nätverksfråga. Eftersom vi vanligtvis mäter latens genom att mäta tur och retur-tid kan en annan källa till latens vara den avlägsna enheten. Om enheten är väldigt upptagen med att göra vad den än måste göra kan den kanske inte svara direkt på ICMP-begäran som den mottog från testvärdet. När det händer kommer det att uppfattas som nätverkslatens men det har faktiskt ingenting att göra med nätverket och din latensmätning ger dig ingen aning om detta.
På liknande sätt kunde användare uppleva latens dethar inget att göra med nätverket. Applicerings latens är kanske lika vanligt som nätverks latens. När servrar blir överbelastade svarar början långsammare. Precis som nätverk när de blir överbelastade. Men server- och applikationslatens är definitivt inte ämnet idag.
Minska nätverksfördröjningen
Det är en (irriterande) sak att uppleva latensoch det är en annan sak att mäta det men vad är det bra om du inte hittar ett sätt att minska det. Det finns flera sätt att göra detta på. I ett nötskal beror på hur man fixar hög latens beroende på vad som orsakar det. Och eftersom den vanligaste orsaken till latens är överanvändning av nätverk, låt oss se vad som kan göras med det.
Nätverkskretsar är inte obegränsade och när de gör detbli överutnyttjad, trängsel uppstår och användare upplever hög latens. Det fungerar precis som motorvägstrafik. Detta gäller särskilt WAN-kretsar som ofta har kraftigt begränsad bandbredd.
Så för att minska latensen är det bästa sättet - du skulle göra dethar gissat det - för att minska nätverksanvändningen. Men naturligtvis är detta inte alltid möjligt. Det är här nätverksoptimering kommer in. Vi kan skriva en hel artikel om WAN-optimering. Faktum är att vi nyligen gjorde det. Och det finns många verktyg du kan använda för att hjälpa till med denna uppgift.
De bästa verktygen för att mäta latens
Som vi nu vet, för att fixa förseningsproblem, förstmåste mäta den och hitta var den kommer ifrån. Det är här verktygen vi ska avslöja kan hjälpa. Vissa mäter helt enkelt latens medan andra hjälper dig att fastställa den. Andra mäter ändå bandbreddanvändning som kan hjälpa eftersom vi vet att överanvändning är den främsta orsaken till hög latens. Verktygen är grupperade efter typ snarare än efter preferenser.
1 - SolarWinds Network Performance Monitor (GRATIS rättegång)
SolarWinds är en av de mest kända tillverkarna avnätverksadministrationsverktyg. Företaget har funnits i evigheter och är också känt för sina flera kostnadsfria verktyg som var och en svarar mot ett specifikt behov av nätverksadministratörer. Flera av de gratis verktygen granskades på dessa sidor eftersom vi diskuterade de bästa TFTP-servrarna för de bästa syslog-servrarna.
SolarWinds Network Performance Monitor, ellerNPM, är SolarWinds flaggskeppsprodukt. Troligtvis ett av de bästa SNMP-bandbreddövervakningsverktygen, det är packat med så många funktioner att vi kan prata om det i timmar. Verktygets bästa fördel är troligen dess enkelhet. Men denna enkelhet kommer inte till priset av flexibilitet. Instrumentpaneler, vyer, diagram och rapporter kan anpassas helt efter dina önskemål eller behov. Verktyget kan ställas in på några minuter och det kan skala från det minsta nätverket till enorma nätverk med tusentals enheter.
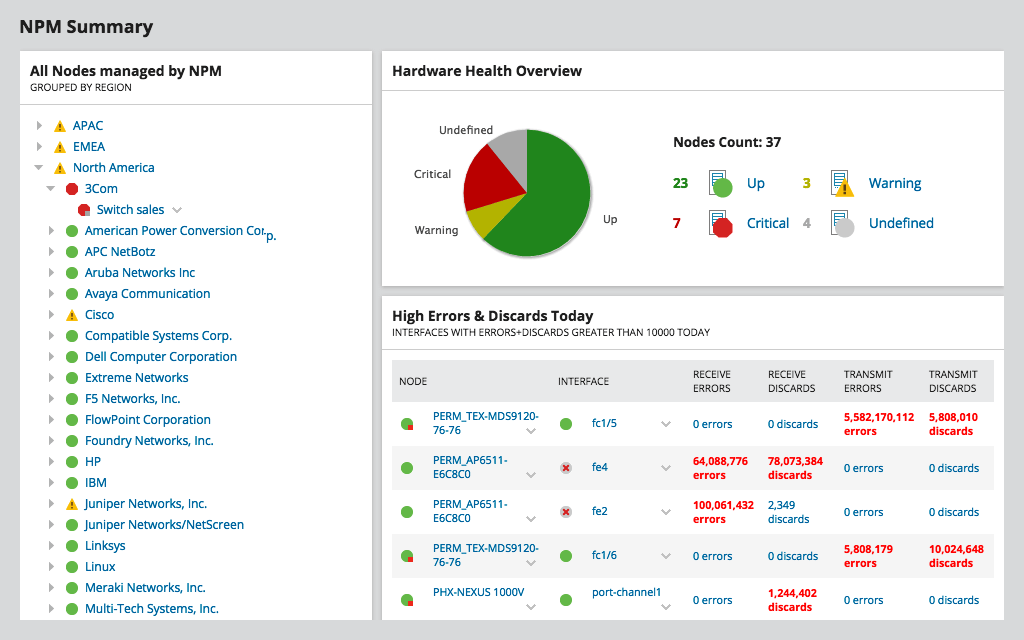
NPM mäter inte direkt nätverksfördröjning,fastän. Men genom att ge dig detaljerad information om bandbreddanvändningen i alla delar av ditt nätverk, kommer du att snabbt kunna identifiera problemställningar där trängsel kan vara orsaken till hög latens.
NPM använder SNMP för att regelbundet polla dina enheteroch läsa deras gränssnittsräknare, beräkna bandbreddanvändning och visa det som diagram. För att konfigurera verktyget krävs endast att du anger en enhets IP-adress och community-sträng. Avancerade funktioner låter dig bygga nätverkskartor och visa den kritiska sökvägen mellan två enheter, en fantastisk funktion när du felsöker latens.
Prissättning för Network Performance Monitor börjar på 2 955 $. Om du vill prova verktyget innan du köper det, finns en fullständig 30-dagars testperiod tillgänglig.
2 - SolarWinds NetFlow Traffic Analyzer (GRATIS rättegång)
En annan utmärkt produkt från SolarWinds, theNetFlow Traffic Analyzer kan ge administratörer en mer detaljerad bild av nätverkstrafik. Det kommer inte bara att visa dig användning och potentiell latens utan den kommer också att visa dig var det sker och ofta vad som orsakar det. Verktyget ger detaljerad information om vad den observerade trafiken är. Till exempel låter verktyget dig ta reda på vilken typ av trafik eller vilken användare som konsumerar mest bandbredd. NetFlow Traffic Analyzers instrumentpanel har flera användbara vyer tillgängliga, till exempel toppapplikationer, toppprotokoll eller topppratare.
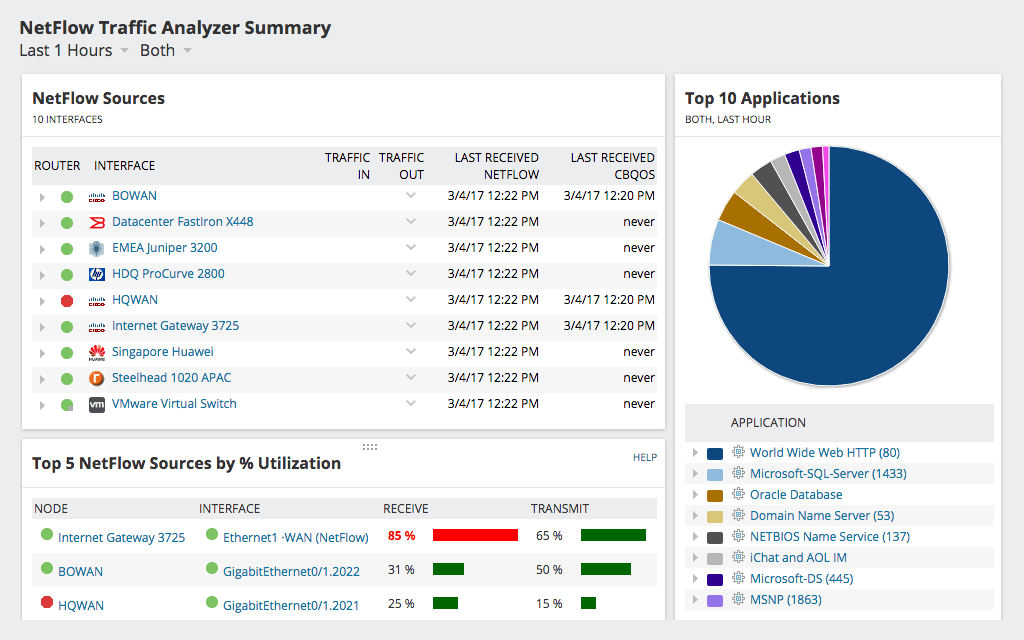
SolarWinds NetFlow Traffic Analyzer använderNetFlow-protokoll för att samla in detaljerad användningsinformation från nätverksenheter. NetFlow-protokollet, som ursprungligen skapades av Cisco, gör det möjligt för enheter att skicka detaljerad information om varje nätverks "konversation", eller flöde, till en NetFlow-samlare och analysator som NetFlow Traffic Analyzer. Denna information innehåller flera element som kan användas för att analysera trafiken. Många andra tillverkare än Cisco inkluderar också NetFlow-funktionalitet eller motsvarande i sin utrustning, ibland kallar det ett annat namn. Nyligen har NetFlow-protokollet standardiserats som IPFIX eller IP Flow Information Exchange av IETF. SolarWinds NetFlow Traffic Analyzer fungerar med alla varianter av protokollet, vilket gör det till ett utmärkt val.
SolarWinds NetFlow Traffic Analyzer är enytterligare modul som installeras ovanpå Network Performance Monitor. Prissättningen börjar på 1 915 $ och varierar beroende på antalet värdar. Och precis som med de flesta SolarWinds-betalda produkter, finns det en kostnadsfri testversion.
3 - Paessler PRTG
Paessler Router Traffic Grapher, eller PRTG, ärett annat bandbreddövervakningsverktyg. Och det är en av de enklaste och snabbaste att installera. Paessler hävdar att du kan vara igång inom några minuter och verkligen tar det inte mycket tid att installera produkten om än lite mer än vad som påstås. Produkten har en automatisk upptäcktsfunktion som innebär att den skannar ditt nätverk och automatiskt lägger till de komponenter som den hittar.
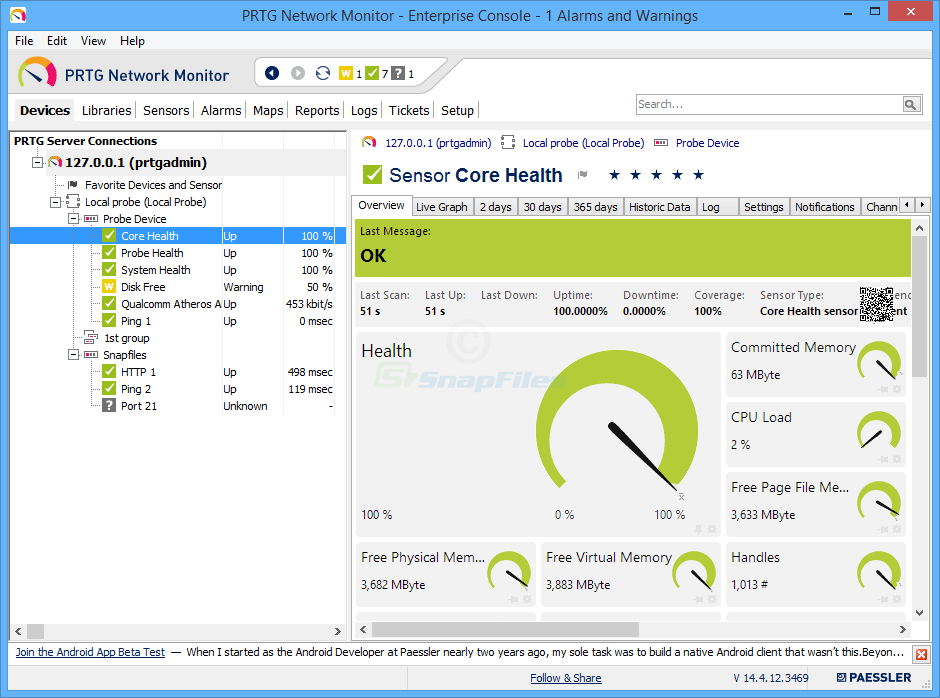
PRTG levereras som standard med flera användargränssnitt,så att du kan välja den som bäst passar dina behov. Det finns en Windows-konsolapplikation, det finns också ett Ajax-baserat webbgränssnitt, och det finns mobilappar för Android och iOS. Och det gör stor användning av varje plattformsfunktioner. Till exempel kommer mobilapparna att tillåta dig åtkomst till alla enhetsdetaljer genom att bara skanna en QR-kodetikett som är fäst på den. Naturligtvis kommer Windows-konsolen att låta dig skriva ut dessa etiketter.
PRTG använder en kombination av tekniker för dessövervakning. Den kommer att använda SNMP-övervakning men också WMI för Windows-enheter och NetFlow och Sflow, två liknande men konkurrerande flödesanalysstekniker. Och verktyget har flera sensorer specifikt utformade för att mäta latens. Det finns en QoS-sensor som kommer att mäta tur-returfördröjningen, en Cisco IP SLA-sensor och en Ping-sensor.
4 - ManageEngine NetFlow AnalYzer
ManageEngine NetFlow Analyzer är en annanNetFlow-baserat övervakningsverktyg som innehåller några avancerade latensövervakningsfunktioner. Verktyget ger en detaljerad bild av nätverksanvändning och trafikmönster. Dess webbaserade användargränssnitt låter dig se trafik efter applikation, konversation, protokoll med mera. Verktygets omfattande instrumentpanel är en av dess bästa funktioner. Det erbjuder några av de bästa mångsidigheterna och låter dig inkludera all information du vill ha. Och för on-the-go administratörer finns det mobilappar tillgängliga.
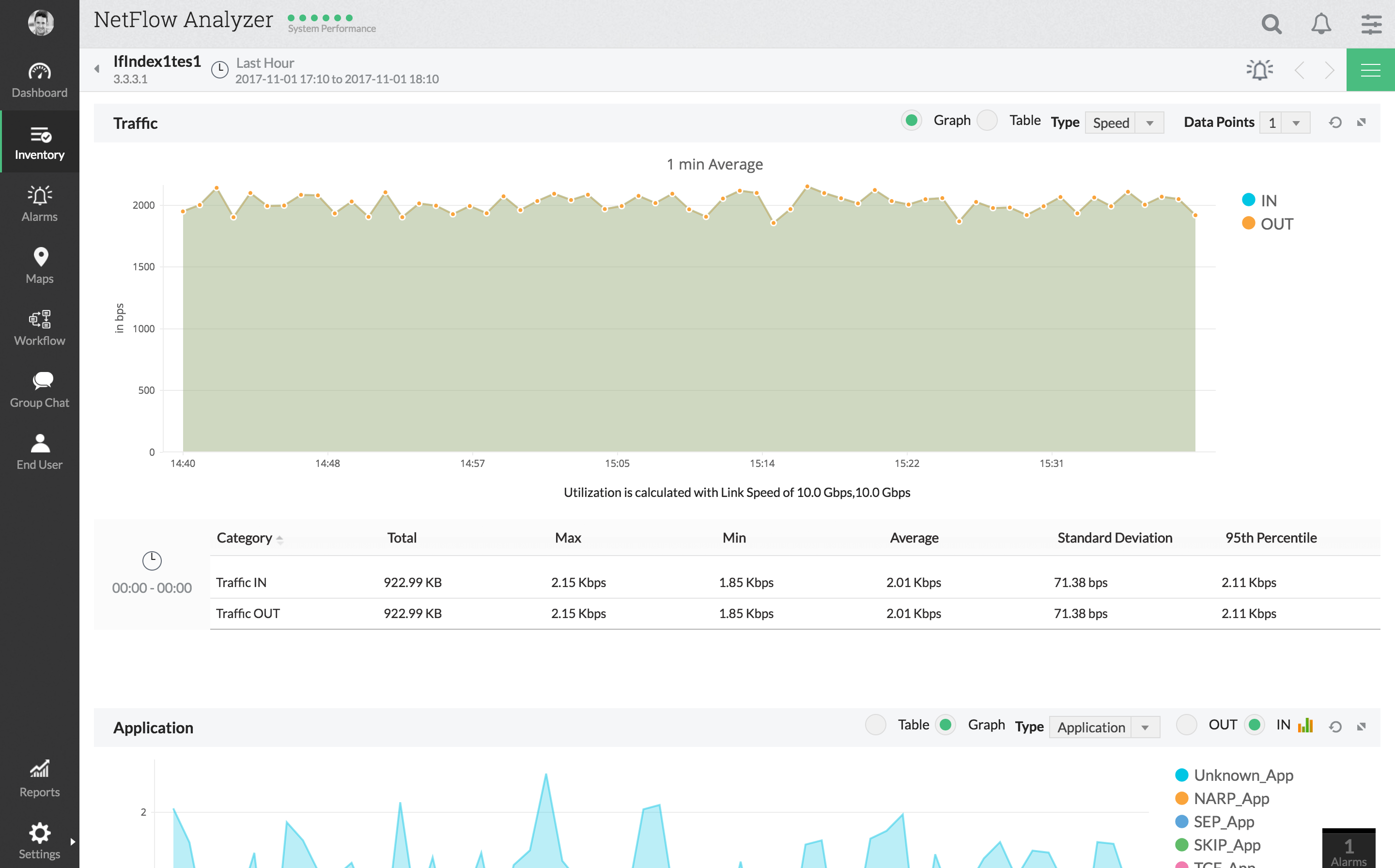
ManageEngine NetFlow Analyzer stöderflera flödeteknologier inklusive NetFlow, IPFIX, J-flow, NetStream och några andra. Som en bonus har också utmärkt integration med Cisco-enheter, med stöd för att anpassa trafikformning och / eller QoS-policy direkt från verktyget.
Och för latensmätning har detta verktyg en WAN Round Trip Time (RTT) -monitor som låter dig övervaka WAN-tillgänglighet, latens och servicekvalitet.
5 - PingPlotter
Trots sitt vilseledande namn är PingPlotter detfaktiskt en grafisk Traceroute-programvara som kan hjälpa till att lösa nätverksproblem. Det här diagnosverktyget visar latens och paketförlust mellan din dator och ett mål. Det låter dig visualisera informationen, påskynda din felsökningsprocess och kan hjälpa till att bygga upp ett mål om du behöver för att övertyga någon om det finns ett problem i deras slut.
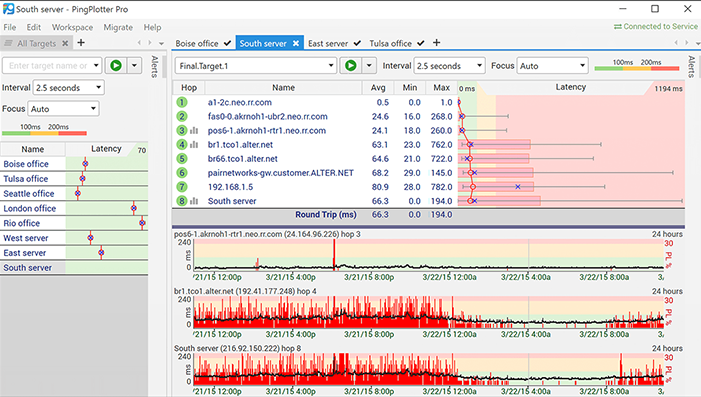
PingPlotter visar nätverksprestanda vid varjehoppa mellan datorn där du kör den och en målwebbplats, server eller enhet. Verktyget testar sökvägen till alla enheter som kan nås via nätverket. Det visar var latens händer, vilket sparar mycket diagnostisk tid.
Det är bra att ha prestationsstatistik,de säger bara att nätverket misslyckades - eller inte misslyckades - under testet och var felet är. PingPlotter har en användbar tidslinjefunktion som ger en djupare förståelse genom att visa exakt när problem uppstår. Detta gör att du kan skilja mellan ett konsekvent fel under hela testet och en kort period med allvarligt fel. Det kan också hjälpa till att korrelera felet med andra samtidiga händelser.
6 - MultiPing
MultiPing är en annan produkt med någotvilseledande namn. Även om den främst använder Ping för att uppnå sin prestation, är MultiPing verkligen ett övervakningssystem, ungefär som SolarWinds NPM. Naturligtvis använder Ping snarare att SNMP betyder att informationen du får är väldigt annorlunda. Förvänta dig inte att se bandbreddanvändning med det här verktyget. En sak du kommer att se är dock latens. Och precis som bandbreddskärmar planerar diagram över bandbredd över tid, kommer denna att plotta latens över tid.
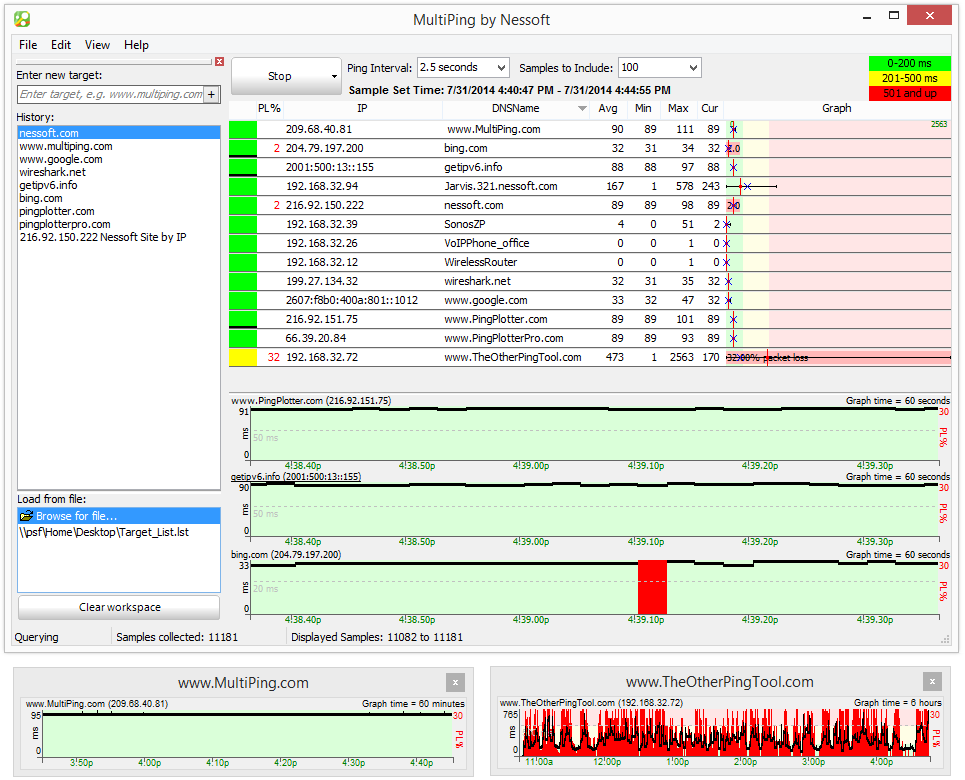
MultiPing visar paketförlust i procentsåväl som minimum, genomsnitt och maximal latens. Den har automatisk upptäckt vilket gör installationen till en mycket enkel uppgift. Produktens användargränssnitt kan konfigureras efter dina önskemål genom att placera dess olika komponenter som du finner lämpligt. Systemet har också larm som kan meddela dig när parametrar är utom räckvidd. Förutom aviseringar kan program startas på varningar.
7 - Ping
Du behöver inte ladda ner eller installera något tilltestlatens, dock. Ping är ett kommando som är inbyggt i de flesta moderna operativsystem. I ett nötskal skickar Ping en serie ICMP-ekofrågor till mål-IP-adressen och väntar på att den ska svara med motsvarande ICMP-ekosvar. Förseningen mellan begäran och svaret kallas för tur-retur-fördröjningen, som också kallas latens. Och när det misslyckas med att få ett svar på en av dess förfrågningar antar verktyget att antingen begäran eller svaret förlorade under transporten och sammanställer paketförlustinformationen som visas när kommandot är slutfört.
8 - Traceroute (Eller Tracert)
På samma sätt Traceroute – eller Tracert om du kommerfrån Windows-världen - kan också användas för latenttestningsändamål. Detta är ett annat kommando som är inbyggt i de flesta operativsystem. Den använder samma typ av ICMP-förfrågningar och svar som Ping men gör det på ett sätt som gör det möjligt att individuellt testa responstiden - eller latensen - för varje nätverkssegment längs vägen. Detta är ännu bättre än Ping eftersom det kan ge dig en ganska bra uppfattning om var det mesta av latensen händer. Så det här verktyget kan inte bara mäta utan också hitta latens.









kommentarer