Det verkar som om nätverk aldrig är tillräckligt snabba. Nätverksprestanda är verkligen den absolut mest klagade frågan när det gäller nätverkssystem. Det finns dock en anledning till det. Nätverksprestanda - eller brist på det - är förmodligen den mest märkbara frågan ur användarens synvinkel. Så när de har till uppgift att felsöka problem med nätverksprestanda måste nätverksadministratörer veta vad de ska leta efter, var de ska leta efter det, och de bör ha tillgång till rätt verktyg.
Idag tittar vi noggrant på felsökning av nätverksprestanda.

Vi börjar, som vi ofta gör, med en mil högvisa vad nätverksprestanda är. När vi närmar oss kommer vi att titta närmare på några av de faktorer som vanligtvis påverkar datornätverkens prestanda. Vi diskuterar först bandbredd och genomströmning som till viss del är två sidor av samma mynt. Därefter talar vi om latens och försening, två mätvärden som ofta är förvirrade. Vi kommer att göra vårt bästa för att belysa ämnet.
Vår nästa affärsorder kommer att vara jitter, en avde mest resultatpåverkande aspekterna av nätverk. Och sist men inte minst diskuterar vi fel som ibland kan vara konsekvensen och ibland symtomen på andra problem. Och eftersom det är mycket viktigt att ha tillgång till rätt verktyg när du felsöker problem med nätverksprestanda, tittar vi på några av de bästa nätverksövervakningsverktygen som kan hjälpa dig med felsökningsarbetet.
Om nätverksprestanda
Wikipedia definierar nätverksprestanda på ett mycket förenklat sätt. ”Nätverksprestanda avser mätningar av servicekvalitet i ett nätverk sett av kunden”. Det finns tre viktiga begrepp i den definitionen. Den första har att göra med mätprestanda. Detta är kritiskt. Nätverksprestanda är något som mäts. Det andra viktiga konceptet är kvalitet. Prestanda avser kvalitet. Och sist men säkert inte minst kunden. Prestanda är något som en användare av nätverket ser eller upplever, inte bara genom mätverktyg. Det är därför det är så viktigt att ha nätverksprestationsövervakningsverktyg som kan göra mätningar ur användarens perspektiv.
Men är inte användarens perspektiv mycketsubjektivt koncept som kan vara svårt att utvärdera? Det är verkligen men med rätt verktyg och tekniker kan det uppnås. Nyckeln är att veta hur varje statistik påverkar upplevd prestanda och det är just vårt ämne för dagen.
Sagt på ett annat sätt är ett nätverk prestandaförmåga att uppfylla användarens förväntningar. Detta är viktigt eftersom det innebär att ett nätverks prestanda är användarberoende. Vissa fall i nätverksanvändning har mycket små prestandakrav medan andra behöver mer. Ett välpresterande nätverk är det där den faktiska prestationen matchar användningen, vilket ger användarna en uppfattning att allt fungerar bra.
Faktorer som påverkar nätverksprestanda
Flera saker kan påverka upplevd prestanda. Vissa faktorer är inte ens nätverksrelaterade. Till exempel kan en server som reagerar långsamt tolkas som ett tecken på försämring av nätverksprestanda. Detta är ytterligare ett skäl till varför vi behöver veta vilka nätverksfaktorer som spelas, eftersom det genom en eliminationsprocess gör det möjligt att identifiera icke-nätverksprestanda.
I följande stycken tittar vi påvilka faktorer och parametrar som samverkar för att ge användarna en uppfattning om bra - eller inte så bra - prestanda. Några av dessa faktorer är fysiska egenskaper hos nätverk som vi vanligtvis inte har kontroll över medan andra är element som ofta kan förbättras, vilket ger användarna en uppfattning om bättre prestanda.
Bandbredd och genomströmning
Bandbredd och genomströmning är på ett sätt två sidorav samma mynt. Dessutom finns det ingen tydlig åtskillnad mellan de två termerna och de används ofta omväxlande. Vi anser att detta är ett misstag eftersom de i själva verket är något olika begrepp.
Bandbredd hänför sig vanligtvis till dataföretagetnätverkets kapacitet per tidsenhet. Det uttrycks vanligtvis i multipla bitar per sekund, med megabit per sekund (Mbps) och gigabit per sekund (Gbps) är det vanligaste. Till exempel har en äldre snabb Ethernet-anslutning en bandbredd på 10 Mbps. Bandbredd är inte något som mäts, och det är inte heller något som varierar över tiden och med ökad användning. Det är en inneboende egenskap hos ett nätverk. Vissa kretsar använder teknik där bandbredd lätt kan ökas eller minskas men i de flesta situationer är det en fast parameter som inte kan modifieras.
När det gäller genomströmning avser det det faktiska beloppetav data som framgångsrikt överförs av tidsenheten. Trehrowput begränsas av tillgänglig bandbredd såväl som det tillgängliga signal-till-brusförhållandet, nätverksfel och hårdvarubegränsningar. De flesta av samma faktorer påverkar nätverksprestanda påverkar produktionen. Faktum är att genomströmning är en nära kusin till prestanda. Allt mer lika, desto högre genomströmning, desto högre upplevd prestanda.
I samband med upplevd nätverksprestanda,bandbredd och genomströmning är viktiga eftersom användningen av bandbredd närmar sig den maximala kapaciteten för ett nätverkssegment försämras prestanda vanligtvis avsevärt. Detta är anledningen till att bandbreddanvändning måste övervakas även om bandbredden är fast.
Latency and Delay
Mycket som bandbredd och genomströmning finns detofta mycket förvirring mellan latens och försening. Detta är en annan situation där två begrepp används omväxlande. Båda har att göra med den tid det tar för data att resa från sin källa till sin destination. Latency beskrivs ofta som tiden från källan som skickar ett paket till destinationen som tar emot det. Det kan också hänvisa till fördröjningsturen för tur och retur som innefattar envägslatensen från källa till destination plus envägsfördröjningen från destinationen tillbaka till källan. I själva verket används tur / retur-latens oftare, främst för att det kan mätas från en enda punkt. Längd på tur och retur utesluter normalt den tid som ett destinationssystem spenderar på att bearbeta paketet och utfärda svaret.
RELATERAD LÄSNING: 6 verktyg för att hantera nätverkskonfiguration för alla dina enheter
Latency är en annan fysisk egenskap hosnätverk. Det är en faktor för avståndet mellan källan och destinationen och ljusets hastighet, som för övrigt också är den hastighet med vilken data reser över alla typer av media. Liksom bandbredd är Latency en fast parameter. Det enda sättet att minska det är att flytta källan närmare destinationen. Att minska avståndet med cirka 100 km kommer att ta bort cirka 1 millisekund latens.
Det finns ganska många andra faktorer som lägger till någrafördröjning till nätverksöverföringarna. Exempelvis uppstår köfördröjning när en gateway tar emot flera paket från olika källor på väg mot samma destination. Eftersom bara ett paket vanligtvis kan sändas åt gången, måste vissa av dem stå i kö för överföring, med en ytterligare försening. Dessutom uppstår behandlingsförseningar medan en gateway bestämmer vad man ska göra med ett nyligen mottaget paket. Bufferbloat kan dessutom orsaka ökade förseningar av en storleksordning eller mer. Kombinationen av förseningar av förökning, kö och bearbetning resulterar ofta i en komplex och variabel nätverks latensprofil.
Latency och försening är de viktigaste faktorerna som påverkarupplevd nätverksprestanda. Lyckligtvis kan de enkelt mätas antingen ensam- eller dubbelt. Dubbelmätning, som beskrivits tidigare, om ofta föredras eftersom den ignorerar destinationens behandlingsfördröjning och ger en riktig mätning av nätverkets latens.
jitter
Jitter är nätverkets största fiende kommunikation och det är relativt enkelt att förklara, men det är detnågot mer komplicerat att förstå hur och varför det kan ha en så negativ effekt på dataöverföringar. Låt oss försöka förklara. Enkelt uttryckt är jitter en variation i försening. Det finns flera faktorer som kan orsaka jitter. Faktum är att många av samma faktorer som påverkar förseningar också påverkar jitter. Till exempel är köförseningar direkt relaterade till kölängden. Och eftersom en typisk kö ständigt varierar i längd, så försenar det också, därmed jitter.
Saken med jitter är att det inte påverkarall nätverkstrafik på samma sätt. När förseningar varierar avsevärt mellan de flera paketen som komponerar ett meddelande (dvs i situationer med höga jitter) kan paketen komma fram till sin destination utanför sekvensen. Låt oss till exempel ta en sändning som består av fyra paket som sänds med intervaller på 10 ms. Den första möter 20 ms latens, den andra 60 ms, den tredje 40 ms och den sista 20 ms. Jag sparar dig den tråkiga matematiken men i en sådan situation kommer det första paketet att komma först, följt av det fjärde, sedan det tredje och slutligen det andra. I vissa situationer skulle detta inte vara ett problem. Till exempel, om vi har att göra med en filöverföring, är paketen numrerade i sekvens och kan enkelt sättas tillbaka i rätt ordning vid mottagningsslutet. Å andra sidan, om det vi har är trafik i realtid, till exempel en strömmande video eller en VoIP-konversation, är vi i problem eftersom paket inte kan sättas samman korrekt, vilket resulterar i pixelformad video eller trasslat ljud. Ur användarens synvinkel har vi ett prestationsproblem.
fel
I viss mån är nätverksfel ett annatfaktor som påverkar nätverksprestanda. Bitfel hänvisar till antalet bitar i en dataström som mottas över en kommunikationskanal som har ändrats på grund av brus, störningar, distorsion eller bitsynkroniseringsproblem. Bitfelfrekvensen eller bitfelförhållandet (BER) är antalet bitfel dividerat med det totala antalet överförda bitar under ett givet tidsintervall. Det uttrycks ofta i procent.
Medan nätverk är mycket robusta och elastiska,de kommer för det mesta återställa från dessa fel med hjälp av flera metoder inklusive inbyggda felkorrigeringsscheman eller vidarebefordran av felaktiga data. Men även om dessa kan vara acceptabla, orsakar de ofta onödiga förseningar, ökade jitter och alla typer av användarupplevda prestationsproblem.
LÄS OCH: Paketförlust - Hur man mäter och fixar
De bästa verktygen för felsökning av problem med nätverksprestanda
Det finns massor av verktyg för mätningnätverksprestanda, inte alla är lika fullständiga som de få vi har valt åt dig. De bästa visar inte bara bandbredd utan också flera bandbredd påverkande mätvärden som latens eller jitter, vilket hjälper dig att snabbt felsöka utfärdade nätverksprestanda.
1. SolarWinds Network Performance Monitor (GRATIS PRÖVNING)
Solarwinds är en av de mest kända leverantörerna av nätverks- och systemadministrationsverktyg. Det är känt för sina många utmärkta verktyg för nätadministration. Bland de mest kända Solarwinds produkter är NetFlow Traffic Analyzer och den Server- och applikationsmonitor. Företaget är också känt för att ha gjort en handfull utmärkta kostnadsfria verktyg, var och en svarar mot ett specifikt behov av nätverks- och systemadministratör. De Avancerad undernätkalkylator och den Kiwi Syslog Server är två utmärkta exempel på de gratis verktygen.
SolarwindsFlaggskeppsprodukten kallas Network Performance Monitor, eller NPM. Detta är en fullständig nätverksövervakningslösning med fantastisk funktionalitet. De SolarWinds NPM frågar alla aktiverade enheter med SNMP-protokolletatt läsa deras operativa statistik och gränssnittsräknare Den lagrar resultaten i en SQL-databas och använder den undersökta informationen för att skapa grafer som visar varje WAN-krets användning samt andra viktiga mätvärden.
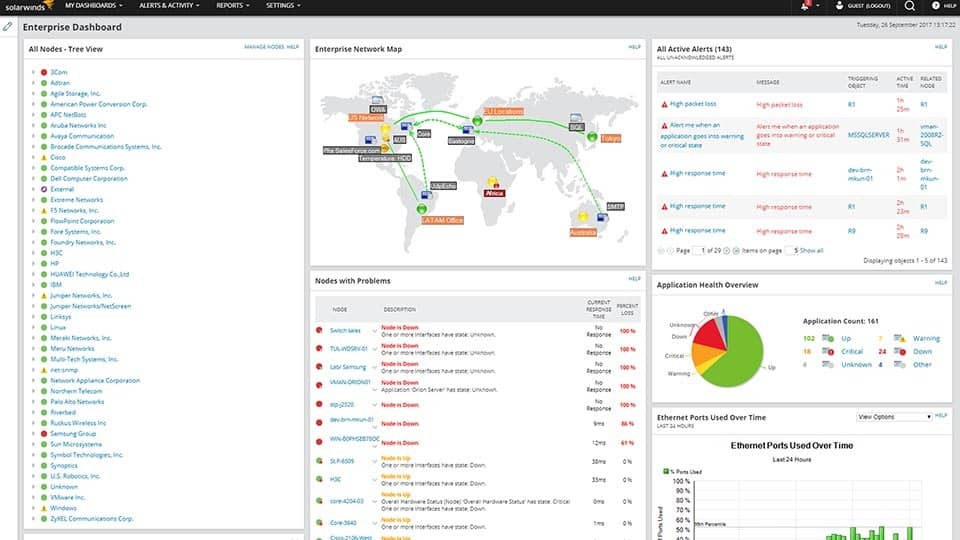
- GRATIS PRÖVNING: SolarWinds Network Performance Monitor
- Nedladdningslänk: https://www.solarwinds.com/network-performance-monitor/registration
SolarWinds Network Performance Monitor kan skrytaett användarvänligt GUI. Med det är att lägga till en enhet lika enkelt som att ange dess IP-adress eller värdnamn och SNMP-communitysträng. Verktyget frågar sedan enheten, listar alla tillgängliga SNMP-parametrar och låter dig välja de du vill övervaka och visa på dina diagram.
Priserna för SolarWinds Network Performance Monitor börjar på 2 995 $ och varierar beroende på antalet enheter som ska övervakas. En detaljerad offert kan erhållas genom att kontakta SolarWinds säljteam.
Om du vill prova produkten innan du köper den, finns det en kostnadsfri 30-dagars testperiod, som för de flesta SolarWinds-produkter.
2. ManageEngine OpManager
De ManageEngine OpManager är en komplett hanteringslösning som kommerhantera de flesta övervakningsbehov. Verktyget kan köras på antingen Windows eller Linux och det är laddat med utmärkta funktioner. Till exempel kan funktionen för automatisk upptäckt grafiskt kartlägga ditt nätverk, vilket ger dig en unikt anpassad instrumentpanel.
Verktygets instrumentbräda är en annan av dess starkapoäng. Det är superlätt att använda och navigera och har funktionsborrning. Om du använder mobilappar är de tillgängliga för surfplattor och smartphones och gör att du kan komma åt systemet var som helst. Sammantaget är detta en mycket polerad och professionell produkt.
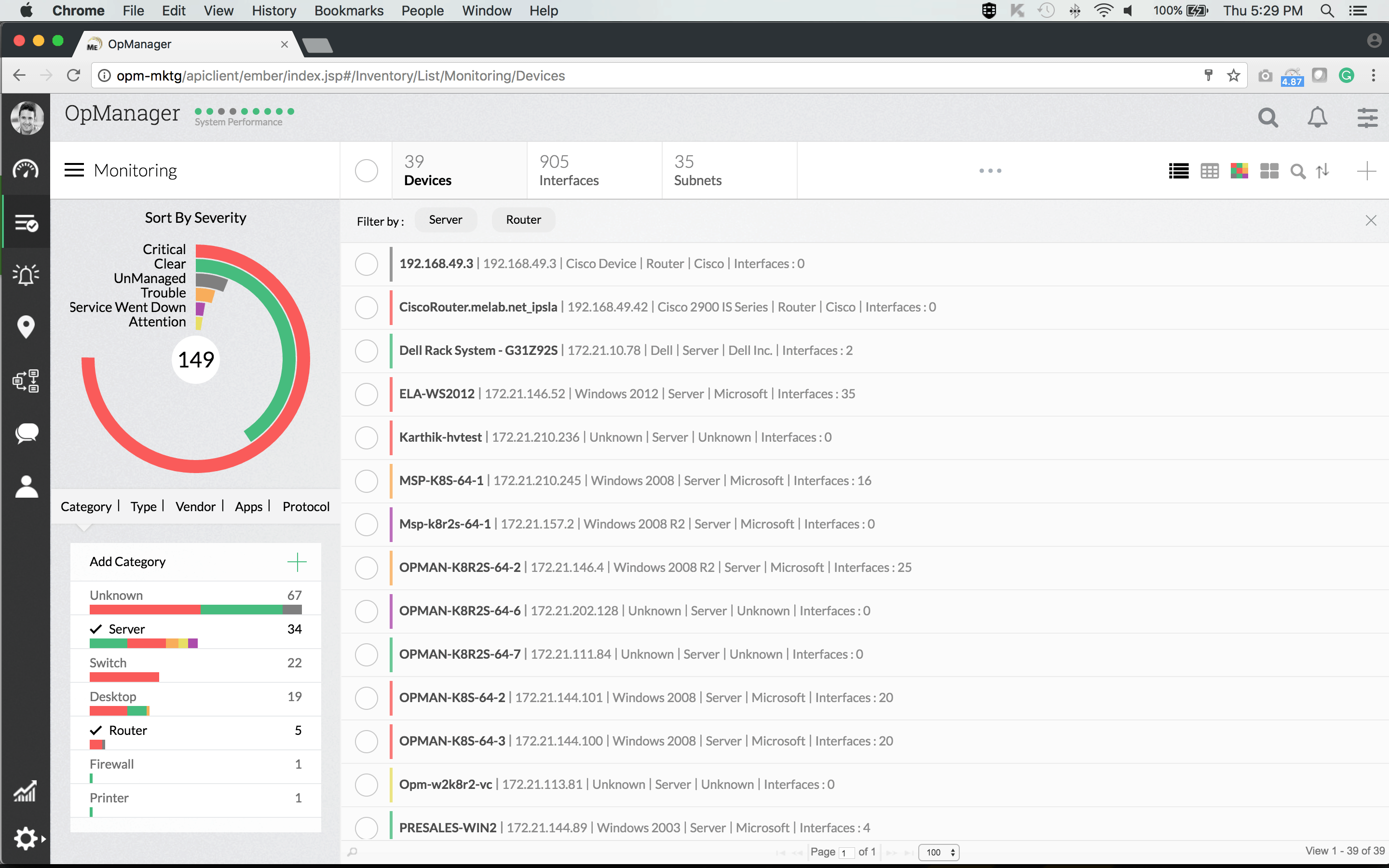
Varnar in OpManager är en annan av produktens styrkor. Det finns ett komplett komplement av tröskelbaserade varningar som hjälper till att upptäcka, identifiera och felsöka nätverksproblem. Flera trösklar med olika aviseringar kan ställas in för varje resultatmätvärde.
Om du vill prova ManageEngine OpManager, få gratisversionen. Det är inte en tidsbegränsad provversion. Det är istället funktionsbegränsat. Det låter till exempel inte övervaka mer än tio enheter. Även om detta kan vara tillräckligt för teständamål passar det bara de minsta nätverken. För fler enheter kan du välja mellan Grundläggande eller den Företag planer. Den första låter dig övervaka upp till 1 000 noder medan den andra går upp till 10 000. Prisinformation finns tillgänglig genom att kontakta ManageEngineFörsäljning.
3. PRTG Network Monitor
De PRTG Network Monitor från Paessler AG är ett agentfritt nätverksövervakningssystem. Paessler hävdar att PRTG Network Monitor kan ställas in på några minuter. Vår erfarenhet visar att det kan ta lite mer än så men att det fortfarande är väldigt enkelt och snabbt tack vare en automatisk upptäcktsfunktion som skannar ditt nätverk, hittar enheter och automatiskt lägger till dem. Verktyget använder en kombination av Ping, SNMP, WMI, NetFlow, jFlow, sFlow, men kan också kommunicera via DICOM eller RESTful API.
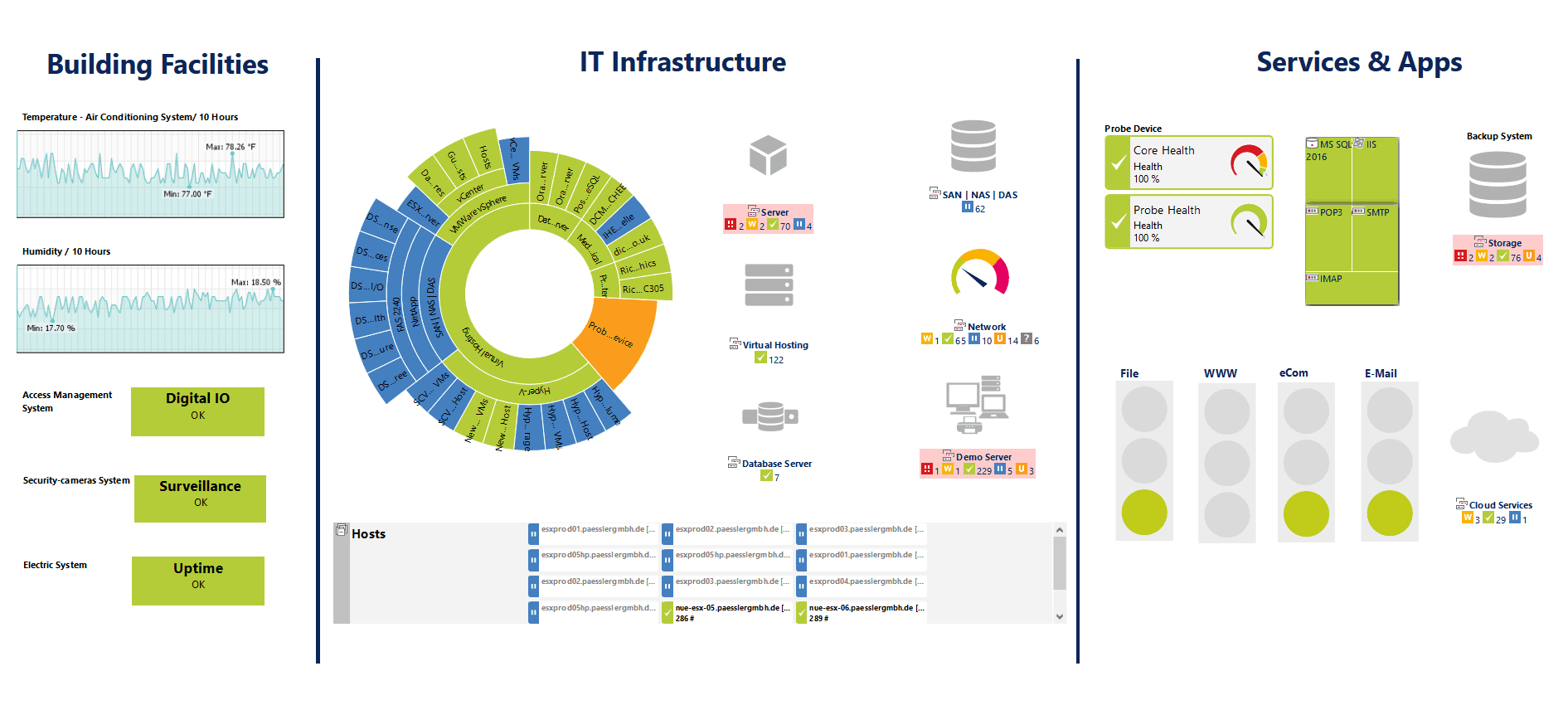
En av styrkorna hos PRTG Network Monitor är dess sensorbaserade arkitektur. Du kan tänka på sensorer som tillägg till produkten förutom att de redan är inkluderade och inte behöver läggas till. Det finns tillägg för praktiskt taget vad som helst. Till exempel finns det HTTP, SMTP / POP3 (e-post) applikationssensorer. Det finns också hårdspecifika sensorer för switchar, routrar och servrar. Totalt finns det över 200 olika fördefinierade sensorer som hämtar statistik såsom responstid, processor, minne, databasinformation, temperatur eller systemstatus från de övervakade enheterna.
De PRTG Network Monitor erbjuder ett urval av användargränssnitt. Den primära är ett Ajax-baserat webbgränssnitt. Det finns också en Windows-företagskonsol samt mobilappar för Android och iOS. En trevlig funktion hos mobilapparna är att de kan använda push-meddelande om alla varningar som utlöses från PRTG. Mer standardmeddelanden via SMS eller e-post finns också tillgängliga. Även om servern bara körs på Windows kan den administreras från alla enheter med en Ajax-kompatibel webbläsare.
De PRTG Network Monitor erbjuds i två versioner. Det finns en gratis version som är fullständig men som begränsar din övervakningsförmåga till 100 sensorer. Observera att varje övervakad parameter räknas som en sensor och till exempel monitor 24-gränssnitt på en nätverksomkopplare kommer att använda 24 sensorer. Om du behöver mer än 100 sensorer måste du köpa en licens. Deras priser börjar på 1 600 $ för 500 sensorer. Du kan också få en gratis, sensor-obegränsad och fullständig 30-dagars provversion.









kommentarer