Network Latency is vaak de grootste vijand vannetwerkbeheerders. Het lijkt overal op te kruipen en je altijd te raken wanneer je het het minst nodig hebt. Aan de andere kant, je hebt het waarschijnlijk nooit nodig. Latentie kan zodanig zijn dat uw netwerk nauwelijks bruikbaar wordt. Wat kan hieraan worden gedaan? Stap één is om latenties te ontdekken. Vervolgens moet u het meten en lokaliseren. Alleen dan kun je er iets aan doen. Om u te helpen, hebben we een lijst samengesteld van testprogramma's voor netwerklatentie die kunnen helpen bij het ontdekken en meten van latentieproblemen.

Voordat we beginnen, zullen we proberen uit te leggen watlatentie is en wat de oorzaak is. Dit zal helpen om beter te begrijpen hoe de verschillende tools kunnen helpen. We zullen ook het belang van latentie onderzoeken en hoe dit het netwerkgebruik beïnvloedt. Vervolgens gaan we kijken hoe we de netwerklatentie kunnen meten. En omdat het nutteloos is om latentie te vinden en te meten als er niets aan wordt gedaan, zullen we ook de latentieverlaging van het netwerk bespreken. We zijn dan klaar om onze lijst met de beste netwerklatentietesttools te presenteren. Maar je zult zien dat het niet alleen een lijst is, we bekijken ook elk van de tools kort.
Wat is netwerklatentie?
In één zin is netwerklatentie een maat voorde tijd die een gegevenspakket nodig heeft om van zijn bron naar zijn bestemming te komen. In een ideale wereld zou er geen latentie zijn. Maar in werkelijkheid zullen er altijd wat zijn. En hoewel latentie onvermijdelijk is, moet men er altijd voor zorgen dat het niet zo belangrijk wordt dat het de normale werking van een netwerk begint te beïnvloeden.
Verschillende factoren dragen bij aan latentie. Ten eerste is er propagatietijd. Hoewel netwerken snel zijn en bits met de snelheid van het licht reizen, duurt het nog enige tijd om de bestemming te bereiken. En hoe langer het pad, hoe langer het zal duren. Om die reden zal de latentie tussen twee computers die duizenden mijlen van elkaar verwijderd zijn normaal hoger zijn dan tussen computers in dezelfde ruimte.
Een andere bijdragende factor wordt genoemdzendvertraging. Dit is een vertraging die door het medium zelf kan worden geïntroduceerd. Het komt ook voort uit de grootte van de datapakketten. Grotere pakketten hebben een hogere latentie naarmate ze meer tijd nodig hebben om te leveren.
Router en andere verwerkingsvertragingen zijn ook eenbron van netwerklatentie. Zelfs op nauwelijks gebruikte circuits waar wachtrijen ontbreken, moet elke router gegevens manipuleren. Het TTL-kopveld moet bijvoorbeeld worden verlaagd.
In feite kunnen veel meer vertragingen de gegevens beïnvloedentransmissie. We kunnen denken aan wachtrijvertragingen die optreden wanneer gegevens niet onmiddellijk kunnen worden verzonden of opslagvertraging wanneer deze in de cache op schijf of geheugen moet worden opgeslagen en vervolgens moet worden opgehaald.
Latentie meten
Het meten van latentie kan ingewikkelder zijn dan hetuitziet. Dit is met name het geval bij het meten van latentie tussen zeer verre punten. Daar zijn een paar redenen voor, maar het is vooral te wijten aan het feit dat zelfs een enorme latentie nog steeds relatief kort is, in de orde van een paar duizendsten van een seconde. Je kunt je vriend niet echt aan de andere kant bellen en hem zeggen: "OK, ik stuur je een pakket, vertel me wanneer het aankomt" en meet de vertraging. De kans is groot dat het pakket aankomt voordat u zelfs klaar bent met praten. Vergeet de timing ervan.
Gewoonlijk wordt de latentie gemeten door een te verzendenpakket dat wordt teruggestuurd naar de afzender en de tijd meet die nodig is om het antwoord terug te laten komen. Het is deze round-trip tijd die wordt beschouwd als de latentie. Er zijn een paar nadelen aan deze evaluatiemethode. Als het retourpad bijvoorbeeld anders is, vertelt het latentiecijfer u niet welke van de voorwaartse of retourpaden latentie ondervinden.
Een ander mogelijk probleem is dat de soortenpakketten die worden gebruikt voor het meten van latentie - meestal ICMP-verzoeken en -antwoorden - worden niet altijd behandeld door de netwerkapparaten met dezelfde prioriteit als sommige ander netwerkverkeer.
Waarom is Latency belangrijk?
Het gemakkelijke antwoord is duidelijk: omdat wanneer latentie te hoog wordt, dit de bruikbaarheid van netwerken kan beïnvloeden. Dus het is geen latentie op zichzelf die belangrijk is, maar kijken is dat wel. Ongewoon hoge - of hoger dan normaal - latentie is vaak een teken dat er iets mis is met het netwerk of op het netwerk. Meestal zal dit het gevolg zijn van congestie. Netwerken zijn als snelwegen en wanneer er te veel verkeer is, vertragen dingen en krijg je een hoge latentie.
Maar gemeten latentie is niet altijd een indicatievan een netwerkprobleem. Omdat we meestal latentie meten door de round-trip tijd te meten, kan een andere bron van latentie het verre apparaat zijn. Als dat apparaat erg druk is om te doen wat het moet doen, reageert het mogelijk niet meteen op het ICMP-verzoek dat het van de testhost heeft ontvangen. Wanneer dat gebeurt, wordt het gezien als netwerklatentie, maar het heeft eigenlijk niets met het netwerk te maken en uw latentiemeting geeft u hier geen idee van.
Op dezelfde manier kunnen gebruikers latentie ervarenheeft niets met het netwerk te maken. Applicatielatentie is mogelijk net zo gewoon als netwerklatentie. Wanneer servers overbelast raken, reageert het begin langzamer. Net als netwerken wanneer ze overbelast raken. Maar server- en applicatielatentie is vandaag zeker niet het onderwerp.
Netwerklatentie verminderen
Het is een (vervelend) ding om latentie te ervarenen het is iets anders om het te meten, maar wat is het goed, tenzij je een manier vindt om het te verminderen. Er zijn verschillende manieren waarop u dit kunt doen. Kortom, hoe een hoge latentie te repareren, hangt af van de oorzaak. En omdat de meest voorkomende oorzaak van latentie het overmatig gebruik van het netwerk is, laten we eens kijken wat hieraan kan worden gedaan.
Netwerkcircuits zijn niet onbeperkt en wanneer zeoverbelast raken, congestie treedt op en gebruikers ervaren een hoge latentie. Het werkt precies zoals snelwegverkeer. Dit geldt met name voor WAN-circuits die vaak een zeer beperkte bandbreedte hebben.
Dus, om latentie te verminderen, is de beste manier - dat zou u doenheb het geraden - om het netwerkgebruik te verminderen. Maar dit is natuurlijk niet altijd mogelijk. Dit is waar netwerkoptimalisatie van pas komt. We kunnen een heel artikel schrijven over WAN-optimalisatie. In feite hebben we dat onlangs gedaan. En er zijn veel tools die u kunt gebruiken om te helpen bij deze taak.
De beste hulpmiddelen voor het meten van latentie
Zoals we nu weten, moet u eerst latentieproblemen oplossenmoeten meten en lokaliseren waar het vandaan komt. Hier kunnen de tools die we gaan onthullen helpen. Sommigen meten gewoon de latentie, terwijl anderen u helpen deze te lokaliseren. Anderen meten toch het bandbreedtegebruik, wat kan helpen, omdat we weten dat overmatig gebruik de belangrijkste oorzaak is van een hoge latentie. De tools zijn gegroepeerd op type in plaats van op voorkeur.
1 - SolarWinds Netwerkprestatiemeter (GRATIS proefversie)
SolarWinds is een van de bekendste makers vanhulpmiddelen voor netwerkbeheer. Het bedrijf bestaat al eeuwen en is ook beroemd om zijn meerdere gratis tools, die elk een specifieke behoefte van netwerkbeheerders aanpakken. Verschillende van de gratis tools werden op deze pagina's beoordeeld terwijl we de beste TFTP-servers van de beste syslog-servers bespraken.
De SolarWinds Network Performance Monitor, ofNPM, is het vlaggenschipproduct van SolarWind. Ongetwijfeld een van de beste SNMP-bandbreedtebewakingsprogramma's, het zit vol met zoveel functies dat we er uren over konden praten. Het grootste voordeel van de tool is waarschijnlijk de eenvoud. Maar deze eenvoud gaat niet ten koste van flexibiliteit. Dashboards, weergaven, grafieken en rapporten kunnen volledig worden aangepast aan uw voorkeuren of behoeften. De tool kan in enkele minuten worden ingesteld en kan van de kleinste netwerken tot enorme netwerken met duizenden apparaten worden geschaald.
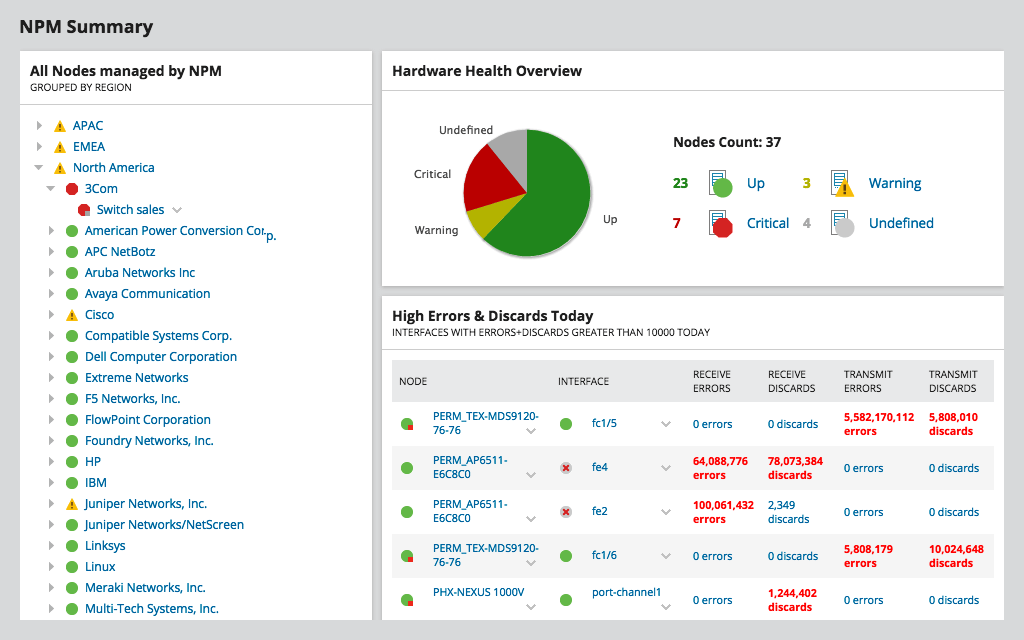
NPM meet niet direct de netwerklatentie,though. Maar door u gedetailleerde informatie te geven over het bandbreedtegebruik van elk deel van uw netwerk, kunt u snel probleemlocaties identificeren waar congestie de oorzaak kan zijn van hoge latentie.
NPM gebruikt SNMP om uw apparaten periodiek te pollenen hun interfacetellers lezen, bandbreedtegebruik berekenen en weergeven als grafieken. Om het hulpprogramma te configureren, moet u alleen het IP-adres en de communityreeks van een apparaat opgeven. Met geavanceerde functies kunt u netwerkkaarten maken en het kritieke pad tussen twee apparaten weergeven, een geweldige functie bij het oplossen van latentie.
De prijs voor de Network Performance Monitor begint bij $ 2 955. Als u de tool wilt proberen voordat u hem aanschaft, is er een volledige proefversie van 30 dagen beschikbaar.
2 - SolarWinds NetFlow Traffic Analyzer (GRATIS proefversie)
Nog een uitstekend product van SolarWinds, deNetFlow Traffic Analyzer kan beheerders een meer gedetailleerd beeld geven van netwerkverkeer. Het laat je niet alleen het gebruik en de potentiële latentie zien, maar het laat je ook zien waar het plaatsvindt en vaak wat de oorzaak is. De tool biedt gedetailleerde informatie over wat het waargenomen verkeer is. Met de tool kunt u bijvoorbeeld achterhalen welk type verkeer of welke gebruiker de meeste bandbreedte verbruikt. Het dashboard van de NetFlow Traffic Analyzer heeft verschillende nuttige weergaven beschikbaar zoals topapplicaties, topprotocollen of toppraters.
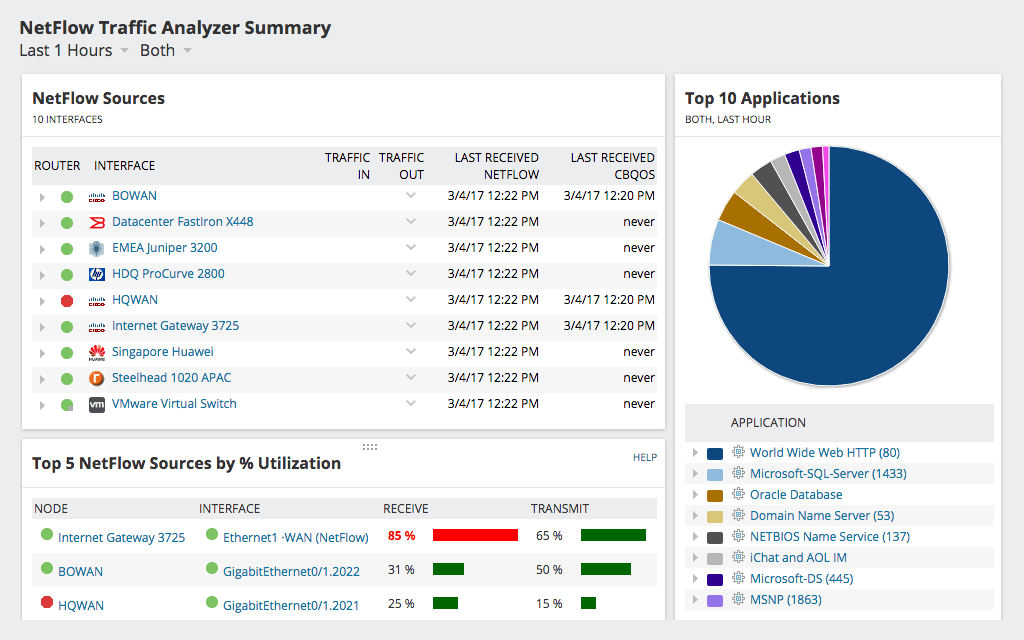
De SolarWinds NetFlow Traffic Analyzer gebruikt deNetFlow-protocol voor het verzamelen van gedetailleerde gebruiksinformatie van netwerkapparaten. Oorspronkelijk gemaakt door Cisco, kunnen met het NetFlow-protocol apparaten gedetailleerde informatie over elk "netwerkgesprek" of stroom naar een NetFlow-verzamelaar en -analysator zoals de NetFlow Traffic Analyzer verzenden. Deze informatie bevat verschillende elementen die kunnen worden gebruikt om het verkeer te analyseren. Veel andere fabrikanten dan Cisco nemen ook NetFlow-functionaliteit of een equivalent in hun apparatuur op, soms noemen ze het een andere naam. Onlangs is het NetFlow-protocol gestandaardiseerd als IPFIX, of IP Flow Information Exchange, door de IETF. De SolarWinds NetFlow Traffic Analyzer werkt met alle varianten van het protocol, waardoor het een uitstekende keuze is.
De SolarWinds NetFlow Traffic Analyzer is eenextra module die bovenop de Network Performance Monitor wordt geïnstalleerd. Prijzen beginnen bij $ 1 915 en variëren afhankelijk van het aantal hosts. En net als bij de meeste door SolarWinds betaalde producten, is een gratis proefversie beschikbaar.
3 - Paessler PRTG
De Paessler Router Traffic Grapher, of PRTG, iseen ander hulpmiddel voor het bewaken van de bandbreedte. En het is een van de gemakkelijkste en snelste om in te stellen. Paessler beweert dat je binnen enkele minuten aan de slag kunt en echt, het instellen van het product kost niet veel tijd, hoewel een beetje meer dan wat wordt beweerd. Het product heeft een functie voor automatisch ontdekken, wat betekent dat het uw netwerk scant en automatisch de gevonden componenten toevoegt.
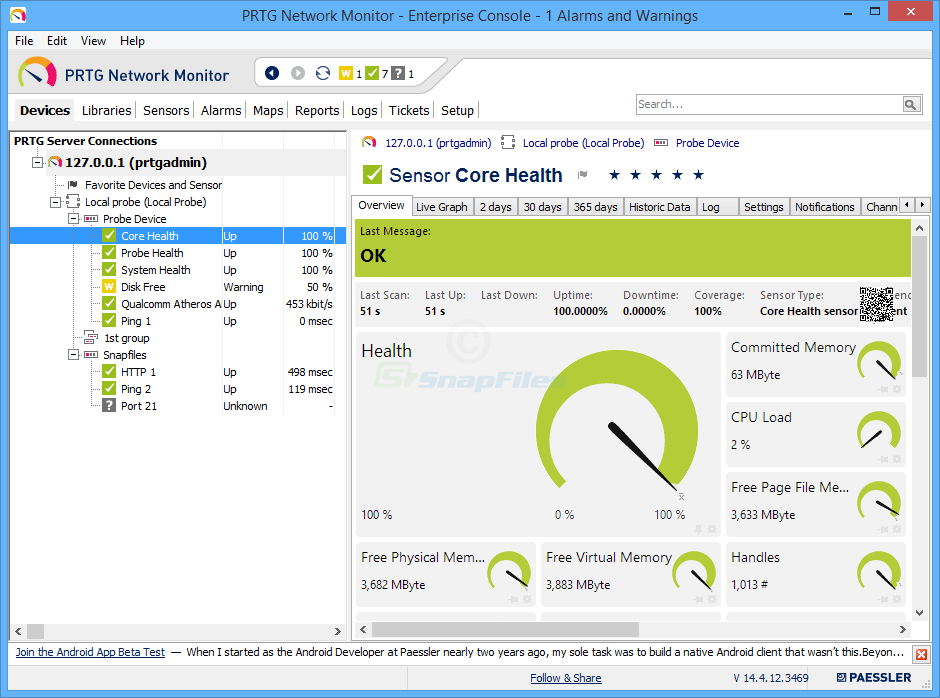
PRTG wordt standaard geleverd met verschillende gebruikersinterfaces,zodat u degene kunt kiezen die het beste bij u past. Er is een native Windows-consoleapplicatie, er is ook een op Ajax gebaseerde webinterface en er zijn mobiele apps voor Android en iOS. En het maakt veel gebruik van de mogelijkheden van elk platform. Met de mobiele apps hebt u bijvoorbeeld toegang tot de gegevens van elk apparaat door eenvoudig een QR-codelabel te scannen dat erop is bevestigd. Natuurlijk kunt u met de Windows-console die labels afdrukken.
PRTG gebruikt hiervoor een combinatie van technologieëntoezicht houden. Het zal SNMP-monitoring gebruiken, maar ook WMI voor Windows-apparaten en NetFlow en Sflow, twee vergelijkbare maar concurrerende stroomanalysetechnologieën. En de tool heeft verschillende sensoren die speciaal zijn ontworpen om latentie te meten. Er is een QoS-sensor die de vertraging van de retour meet, een Cisco IP SLA-sensor en een Ping-sensor.
4 - ManageEngine NetFlow AnalYzer
De ManageEngine NetFlow Analyzer is een andereOp NetFlow gebaseerde monitoringtool met enkele geavanceerde latentiemonitoringfuncties. De tool biedt een gedetailleerd overzicht van netwerkgebruik en verkeerspatronen. Via de webgebaseerde gebruikersinterface kunt u verkeer bekijken per toepassing, per gesprek, per protocol en meer. Het uitgebreide dashboard van de tool is een van de beste functies. Het biedt een aantal van de beste veelzijdigheid en laat je alle gegevens opnemen die je wilt. En voor beheerders die onderweg zijn, zijn er mobiele apps beschikbaar.
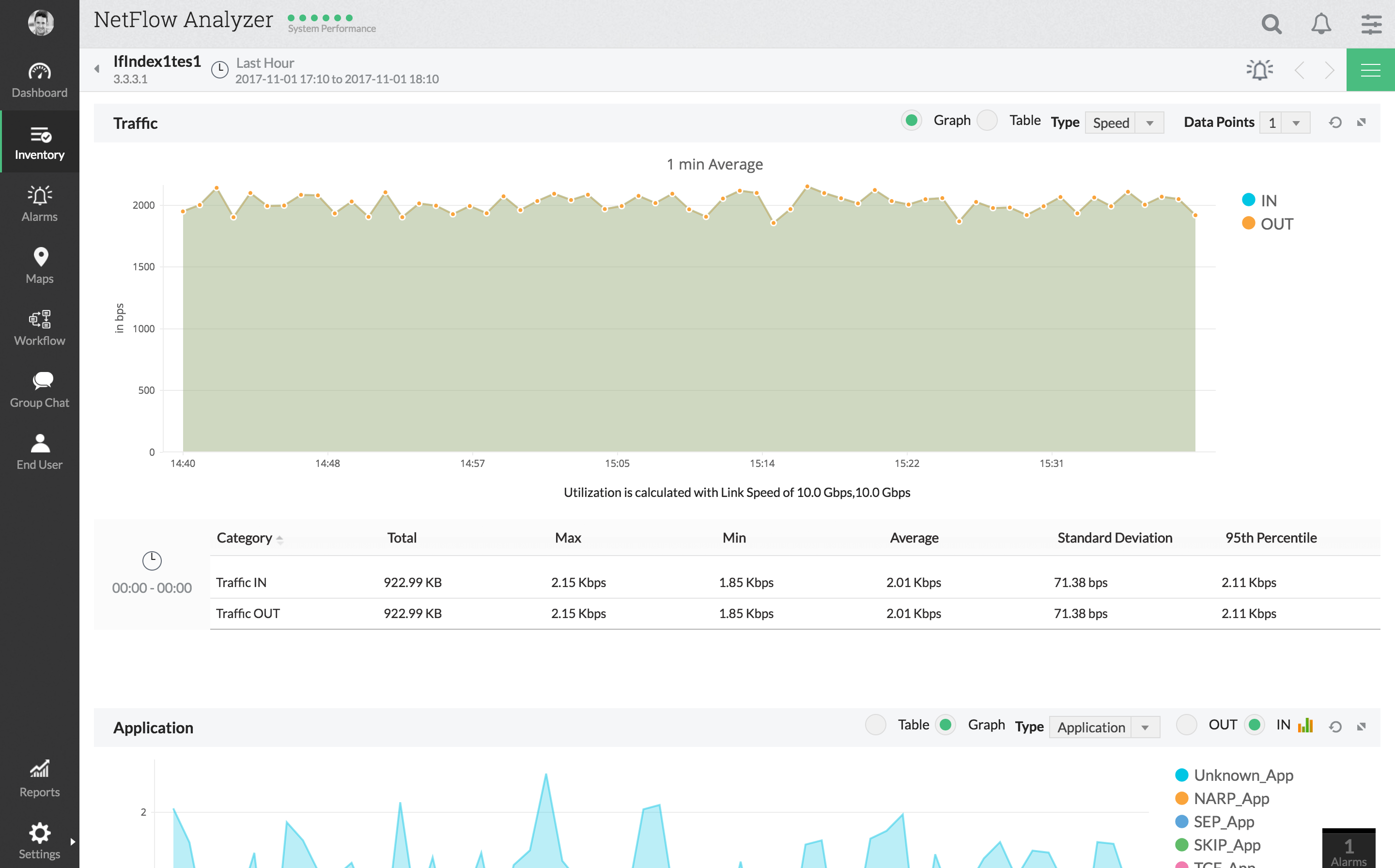
De ManageEngine NetFlow Analyzer ondersteuntverschillende flowtechnologieën waaronder NetFlow, IPFIX, J-flow, NetStream en enkele andere. Als bonus heeft de ook uitstekende integratie met Cisco-apparaten, met ondersteuning voor het aanpassen van verkeersvorming en / of QoS-beleid direct vanuit de tool.
En voor latentiemeting beschikt deze tool over een WAN Round Trip Time (RTT) -monitor waarmee u de beschikbaarheid, latentie en servicekwaliteit van WAN kunt controleren.
5 - PingPlotter
Ondanks zijn misleidende naam is PingPlotter dateigenlijk een grafische Traceroute-software die kan helpen netwerkproblemen op te lossen. Deze diagnostische tool brengt latentie en pakketverlies in kaart tussen uw computer en een doel. Hiermee kunt u de informatie visualiseren, uw probleemoplossingsproces versnellen en helpen bij het bouwen van een case als u iemand moet overtuigen dat er een probleem bestaat.
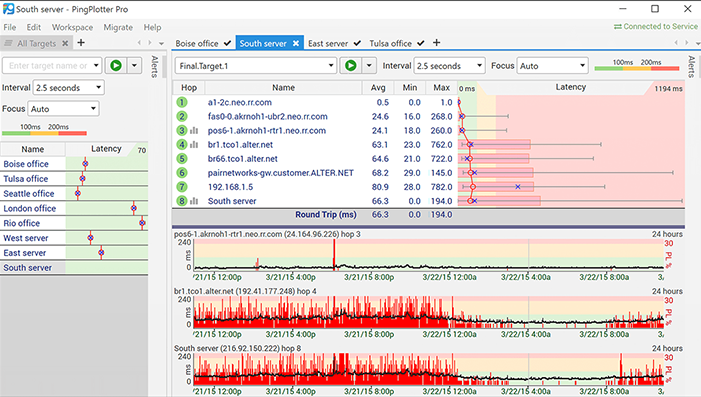
PingPlotter brengt de netwerkprestaties in kaart bij elkespring tussen de computer waarop u het uitvoert en een doelsite, server of apparaat. De tool test het pad naar elk netwerkbereikbaar apparaat. Het laat zien waar latentie gebeurt, waardoor u veel diagnostische tijd bespaart.
Hoewel het handig is om prestatiestatistieken te hebben,ze vertellen je alleen dat het netwerk faalde - of niet faalde - tijdens de test en waar de fout is. PingPlotter heeft een handige tijdlijnfunctie die een dieper inzicht biedt door precies te laten zien wanneer problemen optreden. Hiermee kunt u onderscheid maken tussen een consistente fout tijdens de test en een korte periode van ernstige fout. Het kan ook helpen het falen te correleren met andere gelijktijdige gebeurtenissen.
6 - MultiPing
MultiPing is een ander product met een enigszinsmisleidende naam. Hoewel het voornamelijk Ping gebruikt om zijn prestatie te volbrengen, is MultiPing echt een monitoringsysteem, een beetje zoals NPM van SolarWinds. Het gebruik van Ping in plaats van SNMP betekent natuurlijk dat de informatie die u krijgt heel anders is. Verwacht geen bandbreedtegebruik met deze tool. Een ding dat je echter zult zien, is latentie. En net zoals bandbreedtemonitors grafieken van bandbreedte in de loop van de tijd zullen plotten, zal deze latentie in de loop van de tijd plotten.
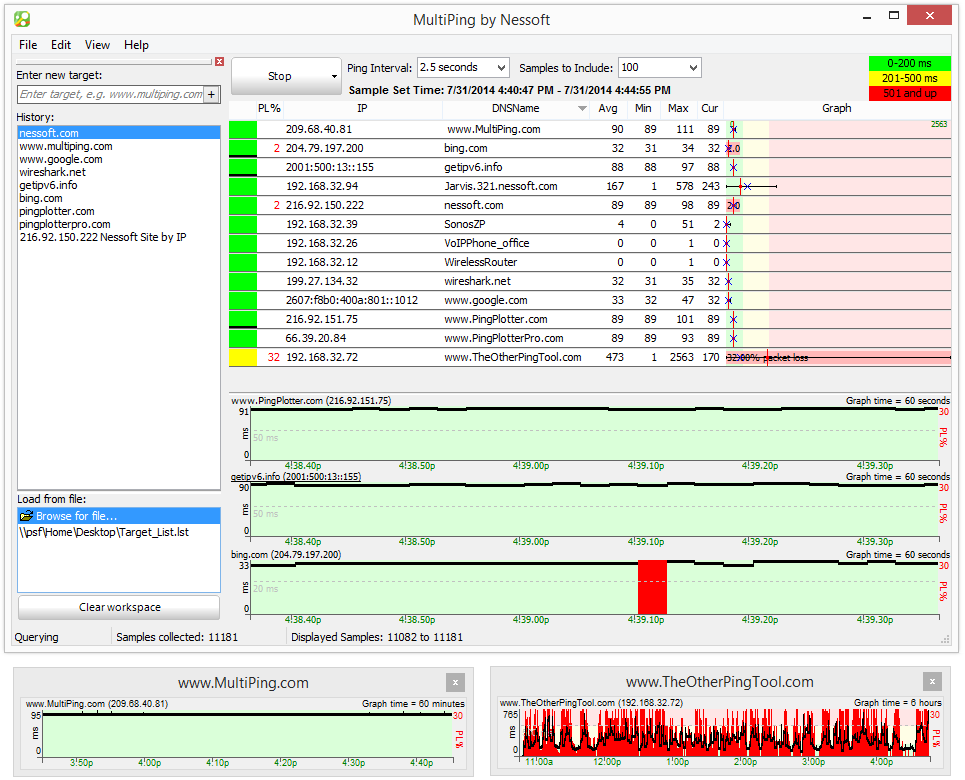
MultiPing toont u pakketverlies in procentenevenals minimale, gemiddelde en maximale latentie. Het heeft automatische detectie waardoor het instellen een super eenvoudige taak is. De gebruikersinterface van het product kan naar wens worden geconfigureerd door de verschillende componenten naar eigen inzicht te plaatsen. Het systeem beschikt ook over waarschuwingen die u kunnen waarschuwen wanneer parameters buiten bereik komen. Naast meldingen kunnen programma's worden gestart met waarschuwingen.
7 - Ping
U hoeft niets te downloaden of te installerentestlatentie, hoewel. Ping is een opdracht die is ingebouwd in de meeste moderne besturingssystemen. Kort samengevat, Ping stuurt een reeks ICMP-echoverzoeken naar het doel-IP-adres en wacht tot deze reageert met overeenkomstige ICMP-echo-antwoorden. De vertraging tussen het verzoek en het antwoord wordt de round-trip vertraging genoemd, ook wel latentie genoemd. En als het geen antwoord op een van zijn verzoeken ontvangt, gaat het hulpprogramma ervan uit dat het verzoek of het antwoord tijdens het transport verloren is gegaan en verzamelt het pakketverliesinformatie die wordt weergegeven zodra de opdracht is uitgevoerd.
8 - Traceroute (of Tracert)
Evenzo Traceroute - of Tracert als je eraan komtuit de Windows-wereld - kan ook worden gebruikt voor latentietests. Dit is een ander commando dat in de meeste besturingssystemen is ingebouwd. Het gebruikt hetzelfde type ICMP-verzoeken en -antwoorden als Ping, maar het doet het op een manier waarmee het de responstijd - of latentie - van elk netwerksegment langs het pad afzonderlijk kan testen. Dit is zelfs beter dan Ping, omdat het je een redelijk goed idee kan geven van waar de meeste latentie plaatsvindt. Dus deze tool kan niet alleen latentie meten, maar ook lokaliseren.









Comments