Mange PDF-lesere har muligheten til å kopiere tekstsammen med bilder, slik at den rike teksten kan limes inn i dokumenter. Men hvis du har å gjøre med PDF-dokument som har hundrevis av bilder, blir det ikke bare arbeidskrevende oppgave, men også tidkrevende å trekke ut dem alle fra PDF-filen manuelt. Fusion PDF Image Extractor ble utviklet for å dempe innsatsen ogviktigst av den tiden som kreves for å samle bilder fra PDF-dokument på et definert lokalt sted. Det er et lite, open source-program for å trekke ut alle bildene fra et gitt PDF-dokument og deretter lagre dem i spesifisert mappe. Det er også ledsaget av iTextSharp-bibliotek og GhostScript-skript for å behandle hele PDF-sider til bilder, slik at brukeren kan trekke ut hele sider som bilder.
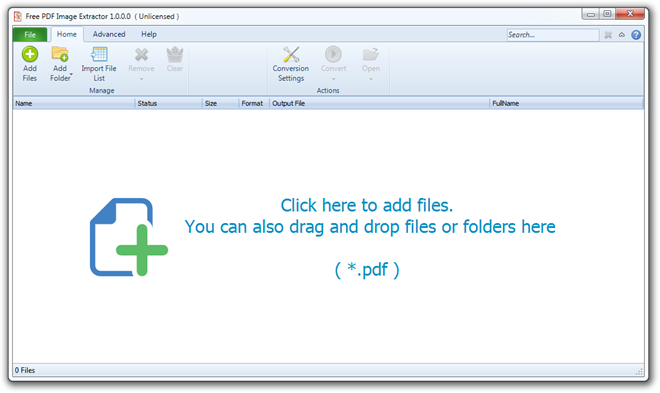
Som standard bruker det ikke GhostScript-skript for å konvertere PDF-dokumentsider til bilder, men du kan aktivere Bruk Ghostscript for PDF-konversjon av hele siden alternativet for å la det konvertere sider til bilder. Du trenger bare å spesifisere PDF-filen etterfulgt av utdatamappe for å starte prosessen med å trekke ut bilder.

Etter at prosessen er ferdig, vil den vise antall sider som er behandlet under bildekstraksjonsoperasjonen.

Kontroller bildene som er trukket ut fra valgt PDF-fil på utskriftsstedet. Hvis du har aktivert GhostScript-alternativet, vil det trekke ut alle sidene som bilder.

Fusion PDF Image Extractor sparer deg for myetid du ville brukt på å trekke ut bilder manuelt fra PDF-fil. Likevel hadde det vært bedre, hvis jeg hadde hatt muligheten til å velge sider jeg vil trekke ut bilder fra.
Last ned Fusion PDF Image Extractor







kommentarer